Operating System
Software is a group of programs that tell a computer how to function.System software and application software are the two broad categories.
- System Software
- Application Software
1) System Software
System Software is made to control hardware and offers a platform on which application software can run. Operating systems, device drivers, file management tools, and language translators like compilers and interpreters are some example.
2) Application Software
Application Software consists of applications that let users carry out particular tasks, like managing data, playing games, creating documents, and browsing the internet.System software serves as the foundation for these applications.An essential component of system software, the operating system serves as a bridge between users and a computer's hardware.It schedules processes, controls data storage, manages hardware and software resources, and makes the overall system stable and effective.
The operating system simplifies the complexity of a computer’s internal operations and allowing users to interact with the system easily. Using a computer or mobile device without an operating system is practically impossible.
The operating system is essentially a complex program that manages how all other software applications are executed. It controls the computer's resources and makes it easier for users and hardware to communicate. In order to run other programs, every computer system needs at least one operating system.These are a few of the most popular kinds of operating systems:
- Windows:Microsoft uses extensively for servers and personal computers.
- macOS:Designed specifically for Apple’s Mac computers
- Linux:Popular open-source operating system commonly used on desktops, servers, and embedded systems.
- Android:Google's operating system primarly made for tablets and smartphones.
- iOS:Apple's mobile operating system for iPads and iPhones.
The operating system can be examined from the following two perspectives:
- User Interface
- Resource Manager
1) User Interface
User interface is part of the operating system that makes easier for people to communicate with computers.It offers a user-friendly control mechanisms like command lines, windows, menus, and icons that let users effectively communicate their commands without having understanding about the complex inner hardware operations.A well-designed user interface improves the user experience by simplifying file management, application launch, and navigation.User interface can be:
- Graphical User Interfaces:like Windows allow users to interact through visual elements such as clickable icons and drag-and-drop features.
- Command-Line Interface:like Linux’s terminal let advanced users execute precise commands through text.
2) Rsource Manager
The Resource Manager component of an operating system is responsible for efficiently allocating, scheduling, and controlling the computer’s hardware and software resources.Controlling CPU time, memory space, disk storage, and input/output devices is necessary to ensure that all running programs and processes receive the resources without intervention.For example,
- When multiple applications run simultaneously,
the
operating system's schedulerallocates CPU time slices to each program, preventing any single application from monopolizing the processor. - Similarly, memory management ensures that each process gets dedicated memory space.
Layered Architecture of Operating System
This architecture separates the operating system into layers, each of which uses the services of the layer below and contributes to the layer above.The layers are:
- User Interface
- Application Programs
- System Services
- Kernel
- Hardware Abstraction
- Hardware
1) User Interface
It is the top layer that provides an interface for users
to interact with the system via graphical user interface or command line interface.For example,
You can click on your word document
2) Application Program
Are user-installed programs that perform specific
tasks, such as browsing internet, playing games, or writing texts.These application programs are depend on system services for operating system level functionality.For example,
Word document,which is a type of application,doesn't opened directly.It asks the Operating system for help via system calls.
3) System Services
Provide core operating system functions like file management, process managment,and memory management,acts as a middleman between application programs and the kernel.For instance,a word application uses operating system–provided system services, such as open() or read(), and these services translate the requests into operations the kernel can understand.
4) Kernel
A central component of an operating system that manages communication between software and hardware. While the Kernel is the innermost part, a shell is the outermost interface for users.For example,The kernel validates the request and ensures permissions to schedules the read operation.
5) Hardware Abstraction
Presents a unified hardware interface to the kernel,
hiding physical hardware details and allowing the operating system to run on different
hardware without being rewritten.For example,
Hardware abstraction converts the kernel's request into hardware specific operations and
hides the differences between hardwares.
6) Hardware
The physical components of a computer like
CPU, RAM, storage devices, and input/output devices.For example,
A specific hardware executes the physical operation
Role and Purpose of Operating Systems
An Operating System is the foundational software that manages a computer’s hardware and software resources. It serves as a bridge between users and the machine, enable us to perform an effective interaction.Operating system is responsible for doing the following tasks:
- Resource Management
- Process Management
- Memory Management
- File System
- Device Management
- User Interface
- Security and Access
- System Monitoring
1) Resource Management
Allocates CPU, memory, disk, and input/output devices efficiently among programs, ensuring optimal hardware use.For example,assume you have two programs such as word document and a game, running simultaneously.The operating system will do:
- CPU Allocation:Using the CPU scheduler,operating system gives a time slice for each program to execute.
- Memory Allocation:Operating system allocates random access memory to each program based on its needs.
- Disk Access:The Operating system manages the disk operation when saving files.
- Input/Output Devices:Operating system manages the process when a game sends audio output to the sound card using device drivers.
2) Process Management
Includes tasks such as handling process creation, scheduling, execution, and termination for multitasking operation.For instance,
- When we open a given program, operating system creates a new process for it.
- Since CPU can run only one process at a time on a single core,the operating system schedules the CPU time among multiple processes.
- Again,each process executed when it gets CPU time.
- Finally,when you close the program,the operating system terminates its process and frees the resources.
3) Memory Management
Tracks and allocates memory space to processes frees unused memory, and prevents conflicts.For example:
- When you open a given program, the operating system allocates a portion of RAM to it.
- The operating system keeps track of which parts of memory are in use by each application to avoid overlapping
- When you close the program, the operating system frees the memory previously allocated to it so other programs can use it.
- Again,the operating system prevents one program from accessing memory space of other program to protect data integrity and security.
4) File System
It is a method used by an operating system to organizes and controls access to data stored on disks using directories, permissions, and file structures.
- Assume,you saved a file named Abc.docx on your computer, and the file system stores Abc.docx within a folder.
- The file system breaks the document into blocks and tracks where each block is stored on the physical disk.
- Again,the file system sets permissions to control who can read, write, or execute the file.
- When you open or save the document, the OS consults the file system to locate the file and check your permissions before granting access.
5) Device Management
Controls hardware like printers, keyboards, and drives using drivers and ensures proper communication.
- If you want to print a document,the OS uses a printer driver to communicate with your specific printer model.
- Then,when you click print button, the OS sends the document data through the printer driver
- The OS manages signals from the printer, such as readiness or errors and informs you if any action is needed.
6) User Interface
Provides command line interface or graphical user interface for user interaction and enables easy launching of programs and managing files.
- You may click on a document icon to open the application.
7) Security and Access Control
Prevents unauthorized access, handles user authentication, and enforces permission rules.
- If your computer has more than one users,When you log in, the OS asks for a username and password to verify your identity.
- Again,after logging in, the OS checks your access rights.
- If some one tries to open a restricted folder without permission, the OS denies its access.
8) System Monitoring
The operating system will help us to monitor system health, performance, and logs.
- In case,if you want to check your computer,You may open the task manager and check system logs
History of Operating System Development
From punch cards to cloud systems,there was an evolution of operating systems.The following are major transition:
- Batch Systems
- Time-Sharing and Multiprogramming
- Emergency of Unix
- Personal Computers and GUI
- Networking and Open Systems
- Mobile and Cloud Era
1) Batch Systems
Starting in the 1950s,early computers didn't have an OS and programs were loaded manually using punch cards or tapes.Later on, the General Motors Research Lab developed one of the first OS for IBM 701 (1956), handling jobs in sequential batches.
2) Time-Sharing and Multiprogramming
In 1960s,OS began supporting multiple programs in memory and terminals enabled interactive sessions.
3) Emergency of Unix
Unix brought modularity, multitasking, and portability via the C language.It serves as a foundation for Linux and macOS in 1970s.
4) Personal Computers and GUI
In 1980s,user-friendly OS became essential and MS-DOS led on IBM PCs. Apple introduced GUI in macOS and Windows 1.0 launched in 1985 as a GUI over DOS.
5) Networking and Open Systems
OS began supporting networking and internet connectivity. In 1991,Linux emerged as an open-source Unix-like OS and Windows 95/98 integrated GUI and system kernel.
6) Mobile and Cloud Era
Currently,smartphones led to mobile OS such as Android and iOS. Modern OS now support cloud computing, virtualization, and high security. Examples:Windows 11, Ubuntu, Chrome OS, and Red Hat.
Design Issues in Operating Systems
Designing an operating system involves balancing multiple critical concerns. The most important design issues are:
- Efficiency
- Robustness
- Flexibility
- Portability
- Security
- Compatibility
1) Efficiency
Maximizes hardware resource usage such as CPU, memory, I/O by using techniques like multitasking, scheduling, and caching to reduce latency and idle time.
2) Robustness
Robustness in an operating system is the ability to continue functioning correctly even if there is a hardware faults, software bugs, or unexpected user actions. A robust OS handles errors without crashing or losing data. For example, modern operating system used process isolation to prevent one faulty application from affecting others, and crash recovery mechanisms like crash recovery mechanism in file systems help restore data integrity after a sudden power failure. This ensures the system remains stable and reliable even under difficult conditions,and enhance user trust.
3) Flexibility
The ability to support different devices and environments. Modular operating system design allows easy integration of drivers and plug-ins.
4) Portability
Allows operating system to work across various hardware platforms using abstraction and portable code.For example, unix-like systems such as Linux and macOS are highly portable, meaning they can be adapted to run on many different types of hardware platforms.
5) Security
Protects user data, software, and hardware by implementing authentication, encryption, access control, and audit mechanisms.
6) Compatibility
Ensures older software runs on a new operating system versions and provides cross-platform support or backward compatibility.
Process
A process is a fundamental execution entity within an operating system, representing an active instance of a program. It possesses its own dedicated memory space, system resources, and execution context, enabling it to operate independently.Typical examples include applications like text editors. The isolation of processes, ensures system stability and security by preventing unauthorized interactions and resource conflicts.
Unlike a static program, a process is the dynamic execution of code, residing in main memory and comprising multiple segments such as stack, heap, data, and text.
During its lifecycle, a process goes through various states such as New, Ready, Running, Waiting, and Terminated,each representing its current condition within the CPU scheduling process.
Each process is defined by a comprehensive set of attributes like process identifier (PID), current state, program counter, priority level, open file descriptors, processor registers, protection domain(boundaries of access rights), and accounting information. These attributes are maintained within the Process Control Block (PCB), a critical data structure that facilitates process management and context switching by the operating system. To view details about processes and threads,download the application via ProcessThreadsView
Process States
It is a process transitions through distinct states during its lifecycle. Each states indicating its execution status within the operating system.The following are main process states:
- New
- Ready
- Running
- Waiting
- Terminated
1) New
In a New state, a process is in the initial phase of its lifecycle, where it is being created and set up by the operating system. During this stage,the operating system allocates necessary resources such as memory space, process control block (PCB), and input/output resources, and loads the program's code and data into memory.However, the process is not yet eligible for execution since it hasn't been admitted to the ready queue.For instance,
- When we open a web browser, the operating system begins creating a new process for it. The browser’s executable file is loaded into memory and system resources such as files are handled.
- After this setup is completed,the process transition converted from New to Ready,and waiting for CPU allocation.
2) Ready
In the Ready state, a process has
completed all necessary initialization and is fully prepared to execute. It has acquired all required resources such as memory,
input/output devices, and open files except the CPU.
Now,the process resides in the ready queue,where it waits for the scheduler to allocate CPU time.
Ready state ensures efficient CPU utilization by keeping processes queued and ready to run as soon as the processor becomes available.For example,When you open multiple applications on your computer, only one application is actively running and using the CPU, the others remain in the ready state.
3) Running
In this state,the process is currently being executed by the CPU.Because,it has been selected by the operating system’s scheduler and is actively performing its assigned tasks. The process has full control over the CPU and can carry out instructions, access memory, and interact with hardware devices.
For example,when you type on a document, the process controlling the editor is in the running state and CPU cycles are dedicated to process your input, rendering the text on screen, and saving changesn until the process is interrupted.
4) Waiting
The process is suspended and waiting for an event or resources such as input/output completion.During this state,the process does not compete for CPU time until the event is triggered.
For instance,when a file is being retrived from a disk, the process waits for the input/output operation to be completed. That means,until the data is available, the process remains in the waiting state and makes the CPU free for other tasks.
5) Terminated
In terminated state,the process has completed its execution or has been forcibly terminated by the operating system or user.In this case,all allocated resources such as memory, file descriptors, and CPU time are released and the process control block is removed from the system.For example, after you closed a notepad, the transition move to the terminated state and operating system cleans up system resources for other processes.
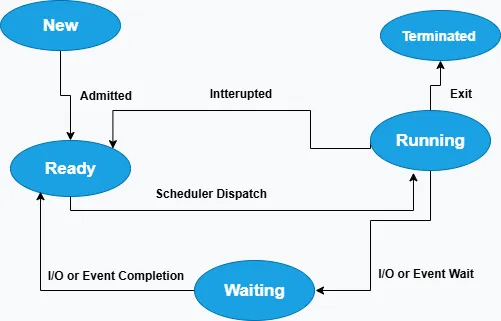
Process States
Thread
A thread is the smallest unit of execution within a process.Multiple threads within the same process may share memory and resources, enabling concurrent execution and better CPU utilization.Threads allow tasks like user interface updates and background processing to run simultaneously.
Threads improve efficiency by allowing parallel execution paths within a single process.They share the same address space but maintain individual execution stacks and program counters and this design enables rapid context switching and responsiveness in multitasking environments.Like a process,each thread has its own program counter, registers, stack,and state. But, all threads of a process share same address space, global variables and other resources such as open files.
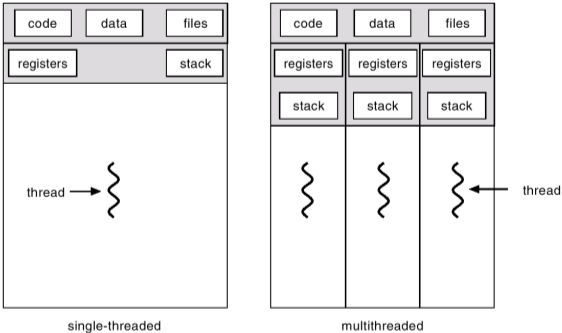
Types of Thread
Threads can be categorized according to who is responsible for their management and scheduling:
- User Level Thread
- Kernel Level Thread
- Hybrid Thread
1) User Level Thread
The threads are managed by a user-level thread library and are invisible to the operating system.They are lightweight but can’t take advantage of multiprocessor systems.Because,the operating system schedules the entire process as a single entity. when you start a program, it may have just one process running,but that process can contain several user-level threads.In this case,the operating system sees only one process, while your program itself manages multiple threads internally.For example,Java virtual threads, GNU Portable Threads.
2) Kernel Level Thread
Every thread that is created, managed, and scheduled directly by the operating system’s kernel through the use of system calls to communicate with the Operating system.In this situation,
operating system is fully aware of each thread in your program and can schedule them individually
on different processors.For instance,in a chrome browser,we may open multiple tabs and each one may run in its own thread.
But,those threads are created using system APIs like CreateThread() and managed by the operating system, not just by the chrome application.For example,Windows threads, Linux pthreads
3) Hybrid Thread
It is a combination of user-level and kernel-level threads, where user threads are mapped to a smaller or equal number of kernel threads.For example,assume,a web browser create many lightweight user threads to handle different tasks which are mapped onto fewer kernel threads.So,the operating system schedules these kernel threads across CPU cores, allowing efficient multitasking.
Thread Models
In general,it describes how user-level threads mapped to kernel-level threads.The following are popular thread models:
- Many-to-One Model
- One-to-One Model
- Many-to-Many Model
1) Many-to-One Model
Multiple user-level threads are mapped to a single kernel thread and the thread management is done by the user-level thread library.This makes thread operations are fast.However,only one thread can access the kernel at a time,limiting concurrency on multiprocessors.
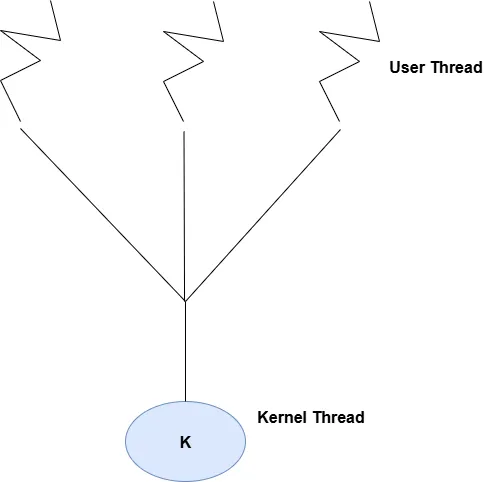
Many to One Model
2) One-to-One Model
Each user-level thread mapped to a unique kernel thread and allows multiple threads to run in parallel on multiprocessor systems.In this case,thread creation is more expensive due to kernel involvement. But,the model offers better concurrency and utilizes hardware efficiently.
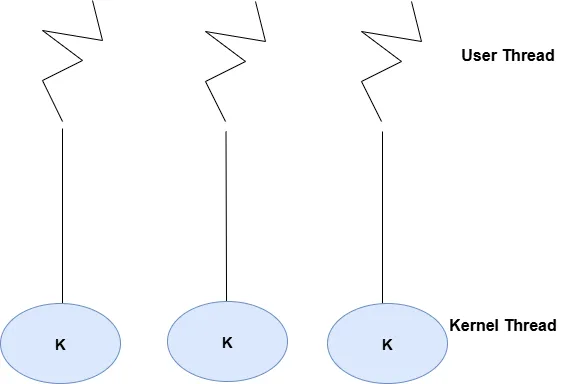
One to One Model
3) Many-to-Many Model
Multiple user-level threads mapped to multiple kernel threads and the model combines the advantages of the previous two models, enabling efficient concurrency and better system utilization.Because,the operating system can create a sufficient number of kernel threads to optimize performance.
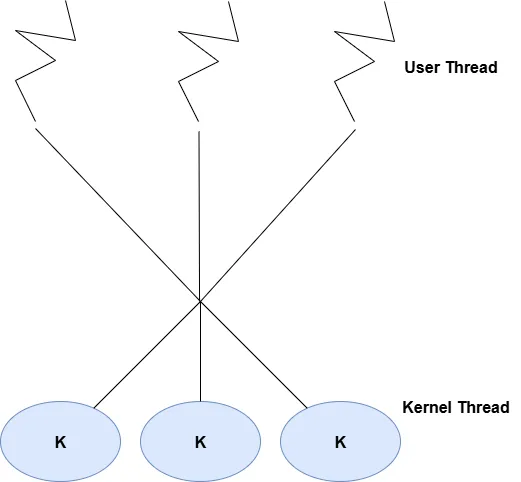
Many to One Many
Thread Usage
It deals about how threads are utilized in software and operating systems to perform tasks more efficiently.Threads are the smallest unit of execution within a process and allow programs to do multiple things at once, improving speed and responsiveness.We can use threads for the following purposes:
- Keeping User Interfaces Responsive
- Parallel Processing
- Handling Multiple Requests
- Background Tasks
1) Keeping User Interfaces Responsive
In a multi threaded application, one thread can handle user input while another loads data or performs background tasks,preventing the application from freezing.For example,in a music player, the main thread manages the play/pause buttons while a separate thread loads songs from the internet.
2) Parallel Processing
Threads let programs to divide large tasks into smaller parts that can run simultaneously on multiple CPU cores(individual processing unit),speeding up processing.For instance,in predicting weather conditions,the entire geographic region can be
divided into smaller zones and each zone is processed by a separate thread running in parallel fashion.
3) Handling Multiple Requests
Servers create threads to handle many client connections simultaneously,allowing them to serve multiple users without delays.For instance,on an online shopping website, when thousands of users browse products, the server creates separate threads to handle each user’s request.
4) Background Tasks
Threads are used to run tasks like downloading files without interrupting the main program flow.For example, when we open notepad and start typing, the main thread is typing the characters, while background threads might be checking spelling
Thread Implementation
It involves creating and managing multiple threads within a process to allow concurrent execution. This improves application performance and responsiveness by utilizing CPU resources efficiently.The following are common activities on thread:
- Thread Creation
- Thread Synchronization
- Thread Scheduling
- Thread Termination
1) Thread Creation
Threads can be created using system APIs using CreateThread() function or language-specific libraries like
pthreads in C and Thread class in Java.For example,we can create a thread using Java:
public class AboutThreadCreation extends Thread {
@Override
public void run() {
System.out.println("Thread: " + Thread.currentThread().getName()); //prints the newly created thread's name, Thread-0
}
public static void main(String[] args) {
AboutThreadCreation t1 = new AboutThreadCreation(); //Object
t1.start(); // Starting a thread(calls CreateThread() in Windows)
System.out.println("From main thread: " + Thread.currentThread().getName()); //prints the main thread’s name, main.
}
}
2) Thread Synchronization
Since threads share resources, synchronization mechanisms like locks, semaphores,and mutexes should be used to prevent conflicts and ensure data consistency.
3) Thread Scheduling
The operating system scheduler allocates CPU time to threads based on their priority, enabling multitasking and efficient processor utilization.
4) Thread Termination
Threads can either be stopped before they complete their intended work or they can finish and terminate normally after completing their task.The release of all resources and the maintenance of system stability are guaranteed by proper cleanup.
public class ManualThreadTermination extends Thread{
private int count= 0; // controling flag
private boolean isrun = true;
@Override
public void run() {
while (isrun && count<=3) {
System.out.println("Thread: " + Thread.currentThread().getName());
count++;
}
System.out.println("Thread terminated.");
}
public void stopThread() {
isrun = false;
}
public static void main(String[] args) throws InterruptedException {
ManualThreadTermination t1 = new ManualThreadTermination;
t1.start();
Thread.sleep(1000); // let it run for 1 second
t1.stopThread(); // Manually requesting to stop the execution of the current thread
}
}
Inter-Process Communication
Inter-process communication, or IPC, is a collection of techniques and systems that enable data exchange and communication between various processes. Processes typically have their own memory spaces, so IPC gives them a means to communicate, coordinate, or synchronize their activities.The main techniques for inter-process communication are:
- Pipes
- Message Queues
- Shared Memory
- Semaphores
- Sockets
- Signals
1) Pipes
Pipe is a mechanism that allows one-way communication between processes, typically between a parent and a child process or between related processes.It is like a tunnel where data flows in one direction.For example,
public class AboutPipes extends Thread {
private PipedWriter wr;
public AboutPipes(PipedWriter wr) {
this.wr = wr;
}
@Override
public void run() {
try {
wr.write("Hello,My parent");
wr.close(); // close the tunnel
} catch (IOException ex) {
ex.getMessage();
}
}
public static void main(String[] args) throws IOException { //Main Thread
PipedWriter writer = new PipedWriter();//character-output stream
PipedReader reader = new PipedReader();
reader.connect(writer); //Connecting the reader with writer(pipe)
AboutPipes child = new AboutPipes(writer); //Object creation
child.start(); //Begins writing execution
BufferedReader br = new BufferedReader(reader); // Parent thread reads message from child
String message = br.readLine();
System.out.println("Parent received: " + message);//Parent gets Child's Message at Read Tunnel
br.close();
}
}
Note: The parent thread refers to the main thread, while the child thread is the thread executing the code outside the main method.
2) Message Queues
It is a data structure that stores messages
sent by one process until another process retrieves them.
It allows asynchronous communication by ensuring messages are received in FIFO order that allows
processes to send and receive messages in an organized queue.
3) Shared Memory
Multiple processes can access the same memory region to exchange data,making it the fastest form of IPC. Because, processes can directly read from and write to memory without kernel intervention for each operation.
4) Semaphores
Used to control access to shared resources by multiple processes and helps in preventing race conditions when processes share memory or other resources.
5) Sockets
By offering a bidirectional communication channel that supports both connection-oriented and connectionless communication, sockets enable processes to interact with one another over a network or within the same machine.For example,ServerSocket is a java class in the java.net package used to build a server that watches for TCP connections from clients.
6) Signals
To inform a process that a specific event has taken place, a signal is utilized. It is an asynchronous communication method that is commonly utilized in Unix systems.addShutdownHook() in java is used to run asynchronously when JVM is shutting down.
public class AboutSignal {
public static void main(String[] args) {
Runtime.getRuntime().addShutdownHook(new Thread() { //register a shutdown hook
@Override
public void run() {
System.out.println("\nSignal received!");
}
});
System.out.println("Application is running. ");
try {
for (int i = 1; i <= 3; i++) {
System.out.println("Doing... " + i);
if(i==2)
{
System.exit(0); //used to call shutdown hook
}
Thread.sleep(1000);
}
} catch (InterruptedException e) {
System.out.println("Main thread interrupted.");
}
}
}
Memory Management (Main Memory)
_____ , , _____Memory management refers to how an operating system manages the distribution, monitoring, and arrangement of a computer's primary memory.
What is Memory?
Memory is central to the operation of modern computers and consists of large array of words or bytes, each with its own address.The CPU fetches instruction from main memory according to the value of program counter.Because,main memory and registers are the only storages that CPU can access directly.In main memory, we can provide protection by using two registers, usually a base and a limit,which is loaded by an operating system. The base register holds the smallest legal physical memory address and the limit register specifies the size of the range.
Memory Management Techniques
_____ , , _____The methods that an operating system uses to efficiently allocate, regulate, and track how much main memory (RAM) is being used by multiple processes.
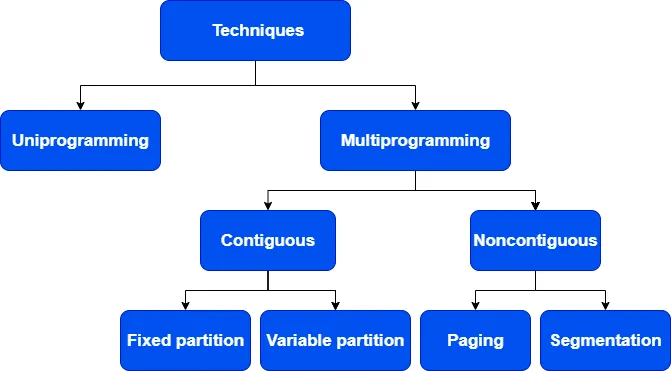
Memory Management Techniques
Uniprogramming is the practice of running a single program in main memory at a time. The CPU either waits for input/output or keeps running that single program until it is completed. The concurrent execution of multiple programs loaded into memory with the CPU switching between them to maximize utilization is known as multiprogramming.
In contiguous memory allocation, each process occupies a single continuous block of main memory that contains all its data and instructions together.In contrast, non-contiguous memory allocation divides a process’s memory into several segments stored in different areas of main memory, which the operating system manages logically as one complete process.
What is binding?
It is the process of mapping instructions and data with a specific memory locations during the execution of a program.Binding can occur at different stages of program execution, such as:
- Compile Time Binding
- Load Time Binding
- Execution Time Binding
1) Compile Time Binding
If the memory location where the process will be loaded is known during compilation,
the compiler can produce absolute code like 0x004.That means,it will replace symbolic addresses such as local variables and functions
with a fixed and actual memory addresses during the compilation process.For instance, the program will refer to the absolute memory location 0x004 rather than a local variable.
2) Load Time Binding
If the exact memory location of a process is unknown during compilation, the compiler creates relocatable/adjusted code using relative address. The addresses in the code are relative, and they are adjusted during the loading phase by adding a base address to each relative addresses.For instance, assume we have a variable x, and the compiler assigns it an offset of 0x04 from the start of the program. Now, suppose the operating system loads the program into memory starting at address 0x100, which becomes the base address. During loading, the loader adjusts the address of variable x by adding the base address to its offset,that is 0x100 (base) + 0x04 (offset) = 0x104. So, x will be loaded at absolute address 0x104.
3) Execution Time Binding
If a program moved to different memory locations while it's running, address binding has to be done during execution time. In this case, symbolic addresses are first translated into relative or relocatable addresses. Then, at runtime, these addresses are dynamically converted into absolute addresses by adding the current base address, which may change as the program moves in memory.For example, if the operating system decides to move the process to a different segment like to 0x200 due to swapping,the memory management unit updates the base address to 0x200. Now, x will be accessed at 0x200 + 0x04 = 0x204.
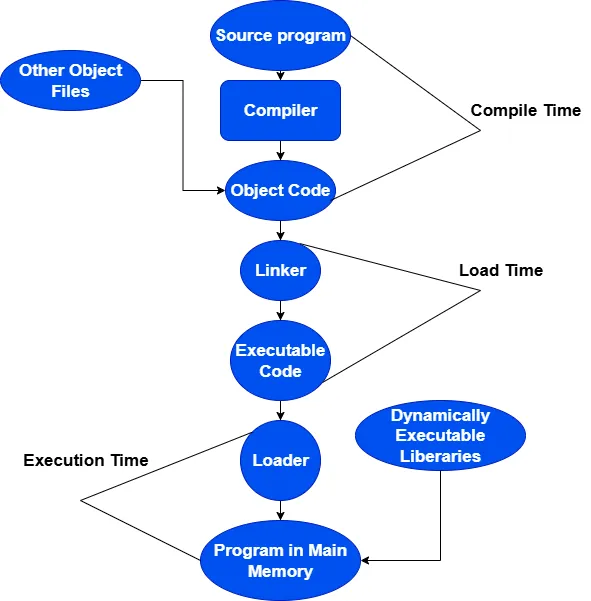
Address Binding
Memory Management Methods
_____ , , _____- Fetch Method
- Placement Method
- Replacement Method
1) Fetch Method
The operating system uses this technique to decide which data or instructions should be loaded into main memory or cache next.
2) Placement Method
Determines the best location for incoming data in main memory to maximize organization and access effectiveness.
3) Replacement Method
Decides which data should be removed from main memory to create room for new data, frequently by applying algorithms such as First-In-First-Out(FIFO).
Memory Address Spaces
_____ , , _____It is the range of addresses that a process, program, or system can use to access memory.The following is classification of memory address space:
- Logical Address Space
- Physical Address Space
1) Logical Address Space
The Logical or virtual address space
is the set of addresses generated by a program during execution.It refers to the
range of addresses a program uses during its execution.These addresses are generated by the CPU whenever the program accesses instructions or data.
However, the memory management unit (MMU) translates logical addresses to physical addresses during runtime rather than mapping them directly to actual physical memory locations.
For example,
Suppose a program generates a logical
address of 0x00004AF3. The memory management unit translates this logical address to a physical address
such as 0x1A04AF3, which is an actual location in RAM.
2) Physical Address Space
The physical address space refers to the actual addresses used by a computer’s main memory to store and access data and instructions. These addresses are directly correspond to real locations on the memory hardware and are seen by the memory unit. During read or write operations, the memory controller and hardware understand physical addresses, as opposed to logical addresses, which are created by the CPU during program execution.
Each logical address generated by a program is translated to a corresponding physical address by the Memory Management Unit,allows the operating system to manage memory efficiently, ensuring isolation and protection between processes.
For instance, after translation, a logical address like 0x00004AF3 might correspond to a physical address 0x1A04AF3, indicates the actual memory cell location in the RAM hardware.
Logical to Physical Address Translation
_____ , , _____The process of mapping the logical or virtual addresses of the CPU to the actual physical addresses in RAM is known as logical to physical address translation.The Memory Management Unit is responsible for this.
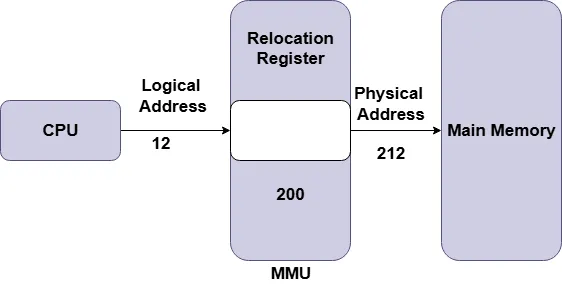
Logical to Physical Address Translation
- In loading(after relocation) and compile-time address binding, logical and physical addresses are identical. Because the logical address produced by the program corresponds to the physical address in memory, when the program's memory location is known at compile or load time. Runtime address translation is not required.
- In an execution-time address-binding scheme, logical and physical addresses are distinct. Because translation happens dynamically during execution, logical addresses differ from physical addresses, and the precise location of memory is not fixed until the program runs.
- The memory management unit, a hardware device with a base address register, performs run-time mapping from virtual to physical addresses by automatically converting logical addresses produced by the CPU into actual physical memory addresses. The memory management unit does this by adding a base register value (R) to the logical address, which ranges from 0 to a maximum value. This yields the physical address, which ranges from R to R + max.That means,Physical Address = Logical Address + Base Register (R).
Swapping
_____ , , _____Swapping is a memory management technique, where the operating system temporarily transfers processes between main memory and secondary storage to optimize RAM usage.When memory is scarce, a process can be swapped out or moved from main memory to secondary storage to free up space for other active processes.
Later, when the process needs to run again, it is swapped in or brought back from secondary storage into main memory and resume execution. This mechanism allows the system to manage more processes.For example, suppose a system has 4 GB of RAM and is running several processes that collectively require 6 GB of memory. The OS can swap out some inactive processes to the hard disk, freeing RAM for active processes.Again,when a swapped-out process becomes active again, it is swapped back into main memory. This process helps to improve system performance and allows multitasking on systems with limited memory.
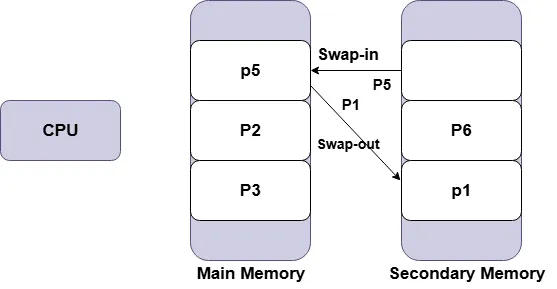
Swapping
Contiguous Allocation
Contiguous allocation is a memory management technique in which each process is
assigned a single continuous block of physical memory.
All of the process's code, data, and stack reside within this one uninterrupted region in RAM.
Because the entire process is loaded into a single block,the memory addresses
used are straightforward and easy to manage. However, this method can lead to fragmentation and
limits flexibility, especially when memory becomes scarce.
For example,
If a process requires 100 KB of memory,the operating system searches for one continuous 100 KB block in RAM and allocates that space as a single unit.
Paging
Paging is a non-contiguous memory allocation technique designed to eliminate external fragmentation.In this method, physical memory is divided into fixed-size blocks called frames, while logical memory used by processes is splited into equally sized blocks known as pages.The operating system uses a page table to manage the mapping process between logical pages and physical frames. This makes it possible to store processes in memory locations that are not adjacent to one another while still ensuring logical continuity from the standpoint of the program.
How Paging Works?
- Logical memory is separated into blocks of the same size called pages, whereas physical memory is separated into fixed-size blocks called frames.Every page corresponds to a frame's size, which is typically a power of two (2n bytes), where n is the offset's bit count.
- When a process is executed, its pages are loaded into any available memory frames from the backing store such as hard disk.
- Each logical address produced by the CPU is splited into two parts: the page number(p), which identifies the specific page in the process, and the page offset(d), which indicates the exact location within that page.
- The page number used as an index into the page table, which stores the frame number or base address of each page in physical memory.The physical address is obtained by adding the page offset to this base address.
- The final physical address is sent to the memory unit to access the required data or instruction.
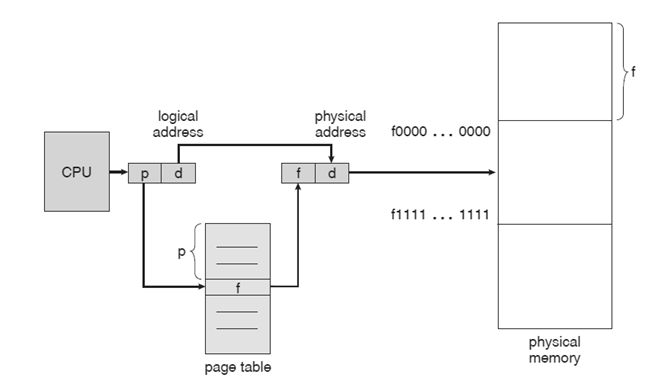
Paging Hardware Diagram.
For instance, suppose logical memory has two pages (1,2) and the page size is 100 bytes.The physical memory frame, which contains the frame number and frame base address,and the page table,which contains the page number and matching frame number, are two more tables that we have.The logical address is (p,d) = (1,20).
Physical Memory Frame
| Frame Number | Frame Base Address |
|---|---|
| 1 | 100 |
| 2 | 200 |
Page Table
| Page Number | Frame Number |
|---|---|
| 1 | 2 |
| 2 | 1 |
Based on the above information,
- Finding the page number,which is 2,is the first step.Next,try to see that the page table's frame number is 1.
- According to the table above,the offset is 200 and the frame base address for that particular frame number is 100.
- Lastly,use the formula to determine the physical address.Physical address = Base + Offset.which is 200 + 20 = 220.
Segmentation
Segmentation is a memory management techniques that organizes a process into logical parts. Each process is divided into segments based on its structural components such as code, data, stack, and heap. Unlike paging,these segments may vary in size and align with the logical structure of the program.
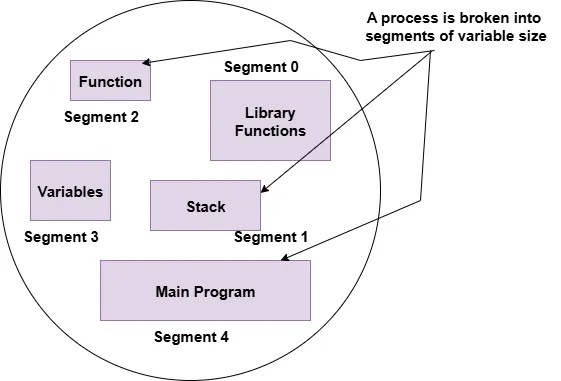
Process Segmentation Diagram.
How Segmentation Works?
- A logical address is divided into two parts,such as segment number(s),which identifies the specific segment, and Offset(d),which indicates the location within that segment.The segment number is used as an index for the segment table.
- The segment table contains,the base address of each segment in physical memory and the limit, which defines the segment’s size.
- To get a correct address,the offset must be less than the segment limit. If the offset is greater than or equal to the limit,it is considered as invalid and results a trap to the operating system as addressing error.
- If the offset is valid, it is added to the segment’s base address to get the physical address of the desired byte in memory.
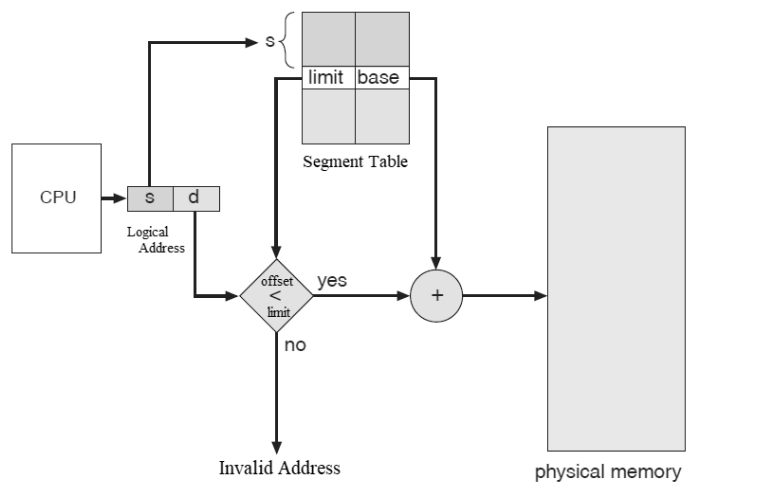
Segmentation Hardware Diagram.
For example,suppose the program generates a logical address,(s,d) = (2,30) and segment table,which contains the following information.
Segment Table
| Segment(s) | Base Address | Limit |
|---|---|---|
| 1 | 300 | 200 |
| 2 | 400 | 400 |
| 3 | 500 | 500 |
Based on the above information,
- The segment number, which is 2, and the base address, which is 400, must be determined first.
- Verify that the offet value, which is 30 less than the 400 limit, is accurate.
- Lastly, use the formula to determine the physical address.Physical address = Base + Offset,which is 400 + 30 = 430.
Segmentation with Paging
Segmentation with paging is a hybrid memory management approach that merges the logical organization of segmentation with the efficiency of paging.In this method, a process is initially splited into segments according to its logical components such as code, data, and stack, and then each segment is broken down into fixed-size pages.The technique uses the advantages of both segmentation and paging.
How Segmentation with Paging Works?
- In this memory management technique, a logical address is divided into three parts: the segment number (s) to identify the segment, the page number (p) to locate the page within that segment, and the page offset (d) to specify the exact byte within the page.
- The CPU first generates A segment number and a segment offset.The segment offset is then further divided into page number and page offset.
- The segment table stores the base address of the page table for each segment. The segment limit is used to check whether the segment offset is valid.
- Each segment’s page table contains the frame numbers (base addresses) for its pages, along with control information such as valid/invalid bits and protection settings.
- To access a memory byte, the segment number first identifies the base address of the page table in the segment table. The page number is then used to find the corresponding frame number in that page table. Finally, the page offset is added to the frame's base address to produce the physical address.
Note :The number of bits required for the segment number depends on the total number of segments in a program. The number of bits for the page number depends on the size of the segment, while the number of bits for the page offset is determined by the page size.
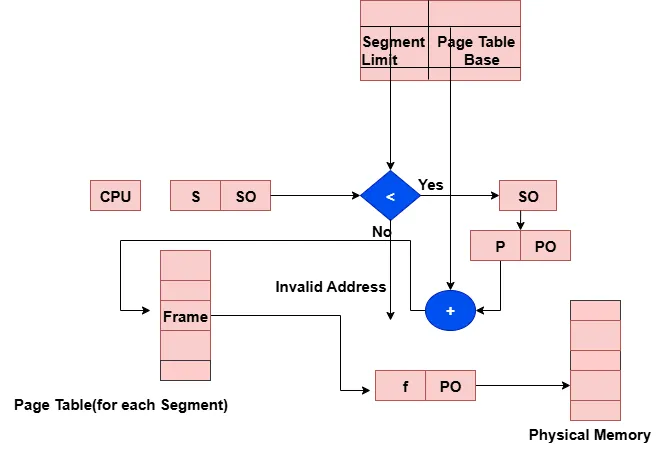
Segmentation with Paging Hardware Diagram
Note:From the above diagram, to determine the correct frame number, do not add the page table base address directly to the page number. Instead, use the page table base address to locate the specific entry corresponding to that page number
For instance, suppose the program creates a segment table and a page table of the designated segment, which contain the following data, and a logical address,(s,p,d)= (1, 2, 200), with a page size of 1KB (1024 bytes).
Segment Table
| Segment(s) | Base Address of Page Table | Limit(No of Pages) |
|---|---|---|
| 1 | 200 | 100 |
| 2 | 300 | 100 |
Page Table at Segment 1
| Page(p) | Frame Number |
|---|---|
| 1 | 2 |
| 2 | 3 |
Based on the above information,
- The segment number, which is 1, and the base address of the page table on that segment, which is 200, must be determined first.Again the page number,which is 2 is less than the segment limit(number of pages)
- A frame of three is indicated by the page number 2, which is derived from the logical address (1,2,200).
- Lastly, we can use the formula to determine the physical address.Physical address = (Frame number × Frame size) + Offset,which is (3*1024) + 200 = 3272 bytes
Direct Memory Access (DMA)
Direct Memory Access is a technique that allows peripheral devices such as hard disk to transfer data directly to and from the main memory without continuous CPU involvement. This improves system performance by freeing the CPU from handling every data transfer.
Steps in DMA Operation
- When a device wants to send or receive data, it first sends a DMA request to the DMA controller.
- The DMA controller sends a HOLD request to the CPU, asking for control of the system buses such as address, data, and control lines.
- The CPU completes its current operation and responds with a HOLD Acknowledge signal, releasing control of the buses.
- Once the CPU enters the hold state, the DMA controller becomes the bus master, taking control of communication between memory and the I/O device.
- The DMA controller performs the data transfer directly between the input/output device and main memory, without CPU intervention.
- After the transfer is complete, the DMA controller returns control of the buses back to the CPU.
Process Management
Basically,a process is a task or unit of work that a processor can carry out in a sequential manner.However, the term process management describes how an operating system manages these procedures.
Process scheduling is the overall mechanism by which the operating system decides which process gets which resource at a given time. It covers every kind of resources that a processes might require such as CPU,Input/Output devices,or Memory.The three levels at which process scheduling functions are as follows:
- Long-term scheduling:Controls the admission of a process into the system.For example, deciding which batch jobs enter to the ready queue
- Medium-term scheduling:Temporarily suspends or resumes processes to optimize resource usage.For instance,it may swap processes in and out of memory
- Short-term scheduling:Determines which ready process gets the CPU next using scheduling algorithms such as FCFS, SJF, Round Robin, Priority Scheduling.
CPU scheduling is a specific type of process scheduling that deals only with processes in the ready queue,which are waiting for the CPU.It determines the order in which processes get CPU time.In CPU scheduling, algorithms can be categorized into preemptive and non-preemptive types. In preemptive scheduling, the operating system can interrupt a process and reassign the CPU to another process before the current one finishes execution. This usually happens when a higher-priority process arrives, a new process has a shorter burst time, or when the time quantum expires in time-sharing systems.
Because shorter and more urgent tasks receive faster attention, preemptive scheduling improves responsiveness and fairness,particularly in interactive or real-time systems.Higher context-switching overhead and more complicated implementation are its disadvantages.
In contrast, non-preemptive scheduling does not allow the operating system to forcibly take the CPU from a running process. Once a process starts execution, it continues until it either finishes or voluntarily enters a waiting state such as for input/output. This approach is easier to implement and has low context-switching overhead, but it is less responsive since short or urgent jobs may wait for long processes to complete.
Scheduling policies, which establish the guidelines and standards the CPU scheduler uses to determine which process to run next, are the foundation of scheduling algorithms. Fairness, effectiveness, and system responsiveness are all balanced in these policies.The choice of scheduling strategy also depends on the type of system:
- Batch System
- Interactive System
- Real time System
1) Batch System
It is a type of system that operating system executes tasks in batches without requiring user input.When there is available space in the main memory, a job was chosen from the job queue and loaded into memory.
Once the job has been loaded into primary memory, it competes for the processor.Again,when the processor becomes available, the processor scheduler selects a job that was loaded into memory and executes it.In contrast, files are processed in batches using the batch strategy.
Users do not interact to the computer directly when using a batch operating system.Before submitting their work to the computer operator, each user prepares it using an offline tool, like punch cards. To speed up processing, jobs with comparable requirements are batched together and carried out collectively.
2) Interactive System
An interactive operating system is one that supports the use of interactive applications. Most operating systems for computers are interactive. An interactive operating system enables direct communication between the user and the computer. This type of operating system executes commands that are entered by the user.
3) Real Time System
It is a kind of system that operates in real-time.This implies that the system must either meet the deadline or guarantee a response within a specified time frame.For example, flight control systems may result in incorrect control commands, endangering the safety of the aircraft, if they are delayed.
The operating system is responsible for managing the following tasks.
- Scheduling
- Process Synchronization
- Process Creation and Termination
- Context Switching
1) Scheduling
Operating systems use scheduling to determine which processes should have access to which resources at what times. Scheduling makes sure that users are responsive, processes run smoothly, and system resources are used effectively.For any algorithm,we have to consider the following important terms:
- Arrival Time(AT):The time,which a process enters the ready queue.
- Burst Time(BT):Required by a process to complete execution.
- Completion Time(CT):The final time that a given process finishes execution.
- Turnaround Time(TAT):The total time a process spends in the system and expressed as
TAT = CT – AT. - Waiting Time (WT):The total amount of time a process spends waiting in the ready queue before it gets CPU time for execution.
Scheduling Algoritms
- First come First Served
- Shortest Job First (SJF) Scheduling
- Shortest Remaining Time First
- Round Robin
- Priority Based Scheduling
1) First come First Served
According to this algorithm, which is the most straightforward CPU scheduling technique, the process that enters the ready queue first is carried out first.In general,it adheres to the First In, First Out rule. For example,
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 5 |
| P2 | 1 | 3 |
| P3 | 2 | 8 |
| P4 | 3 | 6 |
From the above table,we can perform the following scheduling tasks:
- The sequence of execution is p1 → p2 → p3 → p4. since their arrival time has already been arranged.
- They took the following times to finish: p1 = 5, p2 = 8, p3 = 16, and p4 = 22.
- The formula determines their turnaround time. CT-AT = TAT. P1 is 5 units, P2 is 7 units, P3 is 14 units, and P4 is 19 units.
- The formula determines their waiting time. TAT-BT = WT. p1=0 unit, p2=4 units, p3=6 units, and p4=13 units.
- The average turnaround time is 45/4 = 11.25 units (sum of TATs/number of processes).
- Average Waiting Time = 23/4 = 5.75 units (sum of Wt /number of processes).
2) Shortest Job First Scheduling
It selects the process with the smallest CPU burst time for execution,which reduces the average waiting time compared to FCFS.it is non premitive type.For instance,
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 5 |
| P2 | 1 | 3 |
| P3 | 2 | 8 |
| P4 | 3 | 6 |
From the above table
- At time = 0, only P1 has arrived so, P1 will be executed until BT=5.
At time = 5,P2,which has 3 BT, P3,which has 8 BT, and P4,which has 6 BT are available.So,we have to choose P2 from time 5 to 8.Because of its shortest BT.
Choose p4 next,which is executed from time 8 to 14.Because,it has shorter BT.At time 14,last process,p3 is executed from 14 to 22 and execution order will be :p1 → p2 → p4→ p3 - Their completion time: p1= 5 units,p2 = 8 units,p3 = 14 units,and p4 = 22 units
- Their Turnaround Time based on the formula TAT= CT-AT : p1= 5 units,p2= 7 units, p3= 11 units,and p4= 20 units
- Their Waiting Time based on the formula WT = TAT-BT: p1= 0 unit,p2 = 4 units,p3= 5 units,and p4= 12 units
- Average Turnaround Time is :sum of TATs/number of process = 43/4 =10.75 units
- Average Waiting Time = sum of waiting time/number of process = 21/4 =5.25 units
3) Shortest Remaining Time First
The process that has the least amount of CPU burst time left is chosen to run next. In contrast to non-preemptive SJF, if a new process with a shorter burst time arrives, the running process can be preempted.It is a preemptive scheduling algorithm.For example,
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 5 |
| P2 | 1 | 3 |
| P3 | 2 | 8 |
| P4 | 3 | 6 |
From the above table
- In this case,at any time, run the process with the shortest remaining burst time and Preempt if a new process arrives with smaller remaining time.So, at time = 0: Only P1 has arrived and executed with remaining BT = 4
- At time = 1: P2 is available with 3 BT.So,compare with P1 remaining BT =4 , P2 has shorter BT, so preempt P1 ane executed P2
- At time = 2: P3 is available with 8 BT. Remaining BT of P2 is 2,which is less than P3's BT(8).So,P2 will continues
- At time = 3: P4 is available with 6 BT. Remaining BT of P2 is 1,which is less than P4's BT(6).So, P2 will continues
- At time = 4: P2 finishes.So,choose shortest remaining among P1=4, P3=8,and P4=6 , P1 will resumes
- At time = 8: P1 finishes,next shortest remaining Bt: P4=6 and P3=8.So, P4 will execute
- At time = 14: P4 finishes,remaining P3=8.So, run P3
- At time = 22: P3 finishes.So the execution order with preemptions is P1 → P2 → P1 → P4 → P3
- Their completion time: p1= 8 units ,p2 = 4 units ,p3 = 22 units ,and p4 = 14 units
- Their Turnaround Time based on the formula TAT= CT-AT : p1= 8 units,p2= 3 units , p3= 20 units ,and p4= 11 units
- Their Waiting Time based on the formula WT = TAT-BT: p1= 3 units ,p2 = 0 unit,p3= 18 units ,and p4= 8 units
- Average Turnaround Time is :sum of TATs/number of process = 44/4 =11 units
- Average Waiting Time = sum of waiting time/number of process = 29/4 =7.25 units
4) Round Robin
Round Robin is a preemptive CPU scheduling algorithm, where each process gets a fixed time slice, called a time quantum, in cyclic order. If a process does not finish within its time quantum, it is moved to the end of the ready queue, and the CPU is given to the next process.For example,
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 5 |
| P2 | 1 | 3 |
| P3 | 2 | 8 |
| P4 | 3 | 6 |
From the above table,assume Time Quantum = 2 units.
- At time = 0: P1 runs with remaining BT = 5-2=3.
- At time = 2: P2 runs with remaining BT = 3-2=1.
- At time = 4: P3 runs with remaining BT= 8-2 = 6.
- At time = 6: P4 runs with remaining BT = 6-2=4.
- At time = 8: P1 runs with remaining BT 3-2=1.
- At time = 10: P2 runs with remaining BT 1 and finished.
- At time = 11: P3 runs with remaining BT 6-2=4.
- At time= 13: P4 runs with remaining BT 4-2 =2.
- At time= 15: P1 runs with remaining BT 0 and finished.
- At time= 16: P3 runs with remaining BT 4-2 =2.
- At time= 18: P4 runs with remaining BT 2-2 =0 and finished.
- At time= 22: P3 runs with remaining BT 2-2 = 0 and finished.
Finally, Execution order will be :p1 → p2 → p3 → p4 → p1 → p2 →p3 → p4 →p1→p3→p4→p3
- Their completion time: p1= 16 units,p2 = 11 units,p3 = 22 units,and p4 = 20 units
- Their Turnaround Time based on the formula TAT= CT-AT : p1= 16 units,p2= 10 units, p3= 20 units,and p4= 17 units
- Their Waiting Time based on the formula WT = TAT-BT: p1= 11 units,p2 = 7 units,p3= 12 units,and p4= 11 units
- Average Turnaround Time is :sum of TATs/number of process = 63/4 =15.75 units
- Average Waiting Time = sum of waiting time/number of process = 41/4 =10.25 units
5) Priority Based Scheduling
In priority-based scheduling, each process is assigned a priority, and the CPU is allocated to the process with the highest priority. If multiple processes have the same priority, they are scheduled using First-Come, First-Served (FCFS) order. The system may determine a process’s priority based on the factors such as memory requirements, time limits, or other resource usage. Priority scheduling can be either preemptive or non-preemptive.For example,
| Process | Arrival Time | Burst Time | Priority(Lower number → Higher priority) |
|---|---|---|---|
| P1 | 0 | 5 | 2 |
| P2 | 1 | 3 | 3 |
| P3 | 2 | 8 | 1 |
| P4 | 3 | 6 | 5 |
As observed from the above table,
- From arrival time 0 to 1: Only P1 has arrived.So, P1 runs for 1 unit with 4 remaining burst time
- From arrival time 1 to 2: P2 arrives with priority 3.But,still P1 has higher priority, so P1 continues for another 1 unit with 3 remaining burst time
- At arrival time 2: P3 arrives with a highest priority 1 and P3 preempts P1 immediately.
- From arrival time 2 to 10: P3 will runs its full 8 units and finishes at t = 10.Now, ready queue contains P1 with remaining burst time 3 and priority 2,P2 with remaining burst time 3 and priority 3,P4 also arrived at time 3 with remaining burst time 6 and priority 5.But,the highest priority among those ready processes is P1 with priority 2.
- From arrival time 10 to 13: P1 resumes and runs the remaining 3 units and finishes at time 13.
- From arrival time 13 to 16: the next highest priority which is P2 will runs 3 units and finishes at time 16.
- From arrival time 16 to 22: P4 will runs 6 units and finishes at time = 22.Finally, Execution order will be :p1 →p1 → p3 → p1 → p2 → p4
- Their completion time: p1= 13 units,p2 = 16 units,p3 = 10 units,and p4 = 22 units
- Their Turnaround Time based on the formula TAT= CT-AT : p1= 13 units,p2= 15 units, p3= 8 units,and p4= 19 units
- Their Waiting Time based on the formula WT = TAT-BT: p1= 8 units,p2 = 12 units,p3= 0 unit,and p4= 13 units
- Average Turnaround Time is :sum of TATs/number of process = 55/4 =13.75 units
- Average Waiting Time = sum of waiting time/number of process = 33/4 = 8.25 units
2) Process Synchronization
It is a mechanism that ensures processes to access shared resources in safe way.We can implement the following techniques to prevent issues like race conditions and deadlocks:
- Semaphores
- Mutual Exclusion
- Monitors
- Rendezvous
1) Semaphores
It is proposed by Edsger Dijkstra,which is a technique to manage concurrent processes by using a simple non-integer value .Semaphore is used to control processes from accessing shared resources or entering to the critical section at the same time.
A semaphore (S) is apart from intialization is accessed only through two standard atomic operations such as wait(), which is denoted by P from dutch word proberen means to test and signal(), which is denoted by V from dutch word verhogen means to increament.All the modifications in the integer value of the semaphore wait() and signal() operations must be executed indivisibly.This implies,when one process modify the semaphore value,no other process can modify same semaphore value.Here is wait() and signal() operations:
wait()
p(Semaphore S)
{
while(S<= 0);
// no Operation.so,wait until available
S--; //means,take resource
}
From the above definition,if the semaphore or shared integer value is less than or equal to zero,processes not allowed to enter to critical section.However,if semaphore S value is greater than zero,the semaphore will be decreamented and the procss can enter to the critical section.
signal()
V(Semaphore S)
{
S++; //means,finished using a resource and is releasing it back
}
In the case of this signal definition,it indicates that the process is leaving the critical section.
2) Mutual Exclusion
It is also a key principle in process synchronization to prevent multiple processes from accessing shared resource at the same time.Race condition is a situation where more than one processes access same data concurrently.To avoid race condition issue,at a time only one process should enter to the critical section and the rest processes must wait until the resource is released.In the context of mutual exclusion, a given process may goes through three sections:
- Entry section:the preparation phase and the process tries to gain access to the critical section
- Critical section:the main part where the process accesses shared resources.
- Exit section:After finished its work in the critical section, the process will leave it.
For example,assume we have two processes such as p1 and p2 that need to access a single shared printer. So,these processes must execute in orderly manner:
- At entry section,P1 will,check the available printer and if it is free,acquire the lock.
- At critical section,p1 will Print the document,that is accessing shared printer and no other process can print at the same time.
- Finally,at Exit section,p1 will release the lock and make the printer available to others.
Process P2 will follow the same steps.
3) Monitors
It is a high-level synchronization construct that allows multiple pocesses to access a shared resource in safe way.Monitor is like an object in object oriented programming that hide shared variables and procedures needed to prevent from race conditions.For instance,
public class AboutMonitors {
private int[] buffer; //Array to store items
private int count; //Current number of item inside the buffer
private int in, out; //index that the item is inserted and removed respectively
private int size;//Maximum capacity of the buffer
public AboutMonitors(int size) {
this.size = size;
buffer = new int[size];
count = in = out = 0;
}
public synchronized void insert(int item) throws InterruptedException { // Producer will inserts item
while (count == size) {
wait(); // wait for space
}
buffer[in] = item;
in = in + 1;
count++;
notifyAll(); // notify consumers
}
public synchronized int remove() throws InterruptedException { // Consumer removes item
while (count == 0) { // buffer empty
wait(); // wait for item
}
int item = buffer[out];
out = out + 1;
count--;
notifyAll(); // notify producers
return item;
}
static class Producer extends Thread { // Producer thread
private AboutMonitors buffer;
public Producer(AboutMonitors buffer) {
this.buffer = buffer;
}
public void run() {
for (int i = 1; i&l;= 2; i++) {
try {
buffer.insert(i);
System.out.println("Produced: " + i);
Thread.sleep(100);
} catch (InterruptedException e) {e.getMessage(); }
}
}
}
static class Consumer extends Thread { // Consumer thread
private AboutMonitors buffer;
public Consumer(AboutMonitors buffer) {
this.buffer = buffer;
}
public void run() {
for (int i = 1; i<= 2; i++) {
try {
int item = buffer.remove();
System.out.println("Consumed: " + item);
Thread.sleep(150);
} catch (InterruptedException e) { e.getMessage();}
}
}
}
public static void main(String[] args) {
AboutMonitors buffer = new AboutMonitors(3);
Producer p = new Producer(buffer);
Consumer c = new Consumer(buffer);
p.start();
c.start();
}
}
4) Rendezvous
Is a synchronization mechanism primarily used in message-passing systems, where two processes meet or rendezvous to exchange information simultaneously, ensuring coordination without shared memory. That means,processes should synchronize at the rendezvous point.For example,
Semaphore notifyA = 0; //means,no resource is currently available
Semaphore notifyB = 0; //means,no resource is currently available
// Process A
send_message();
signal(notifyA); //Now,notifyA becomes 1 and tell B that A has sent the message
wait(notifyB); //Now,A is waiting for confirmation from B until B receives it
// Process B
wait(notifyA); // Wait for A to send message
receive_message();
signal(notifyB); //Tell A that B has received it
Process Creation and Termination
Operating system creates a new process when a given program is opened and terminates it when completed or aborted.As we know,each process is assigned a unique ID and resources.For instance,
public class ProcessCreation {
public static void main(String[] args) {
try {
System.out.println("Notepad process starts.");
ProcessBuilder pb = new ProcessBuilder("notepad.exe");
Process child = pb.start(); // Starts child process
System.out.println("Child process started.");
int exitCode = child.waitFor(); // Wait for child process to terminate
System.out.println("Child process terminated: " + exitCode);
System.out.println("Notepad process also terminates.");
} catch (Exception e) {
e.printStackTrace();
}
}
}
Context Switching
Interrupts cause the operating system to change the CPU from its current task and to run a Kernel routine.So,when an interrupt occurs, the system needs to save the current context(information about current process) of the process currently running on the cpu.So that the system can restore that context when its processing is done.
Switching the CPU to another process requires performing a state save of the current process and a state restore of a different process.This process is called context switching.In multiprogramming or multitasking systems, context switching is necessary.Because, several processes compete for the CPU and operating system performs these switches to maintain fairness and ensure that all processes remain responsive. Context-switch time is pure overhead,because,the system does no useful work while switching.For example,
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 5 |
| P2 | 1 | 3 |
In the above table,assume time quantum is 2 units.Execution Order with Preemption will be:
- At time 0: P1 runs for 2 units and remaining BT will be 5-2 = 3.In this case,context switch will occurs.
- At time 2: P2 runs for 2 units and remaining BT will be 3-2 = 1.Again,context switch occurs.
- Finally,the execution order will be :p1 → CS → p2 →CS → p1 →CS → p2 → CS → p1
Deadlock
In a multiprogramming environment, multiple processes may compete for a limited number of system resources.When a set of processes permanently blocked, either due to competing for resources or waiting for communication with each other,deadlock will occure.A process will be in deadlocked state, if it is waiting for an event that will never happen.Under normal operation, a process typically uses a resource in the following sequence:
- Request:Every process will request an instance of a resource to do something.In this case, if the resource is available,it is allocated.Otherwise, the process must wait until the resource becomes free.
- Use:Process will use the resource to perform its operations, usually through system calls.
- Release:After finishing its task,the process releases the resource back to the system, again using system calls.
In a given process,the following conditions can create a deadlock:
- Mutual Exclusion:If only one process use a particular resource and no other process can access a resource that has already been allocated to another process.
- Hold and Wait:If a process that is currently holding at least one resource and waiting to acquire additional resources that are currently being held by other processes.
- No Preemption:If resources cannot be forcibly taken away from a process.
- Circular Wait:If there is circular chain of processes exists where each process is waiting for one or more resources held by the next process in the chain.
Deadlock Solution Strategies
Approaches used in operating systems to handle deadlocks effectively.The following can be used as a deadlock solution strategies:
- Deadlock Detection and Recovery
- Deadlock Avoidance
- Deadlock Prevention
- Deadlock Igronance
1) Deadlock Detection and Recovery
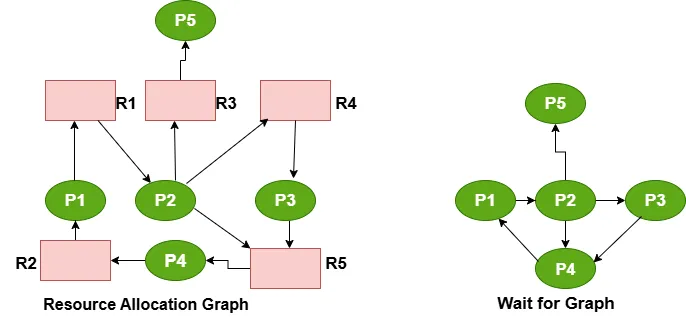
As we discussed,deadlock prevention and avoidance used to stop deadlocks before they happen.But, deadlock detection and recovery allows deadlocks to occur.Later on,it detects and recovers to continue system operation. To do this,the operating system periodically checks the system state to ensure if a deadlock has occurred.To detect deadlock,we may use the following data structures:
- Resource Allocation Graph (RAG)
- Wait for Graph
A) Resource Allocation Graph
It is a graphical representation used in operating system to detect deadlocks in concurrent systems.Resource Allocation Graph is used to visualize how resources are assigned to processes, and how processes are waiting for resources.It helps in detecting deadlocks, especially in systems with single-instance resources.The graph consists of a set of vertices V and a set of edges E.V partition into two types such as:
- P = {P1, P2, …, Pn}, the set consisting of all the processes in the system.
- R = {R1, R2, …, Rm}, the set consisting of all resource types in the system.
During resource allocation graph, the request edge is denoted by P1 → Rj and assignment edge is indicated by Rj → Pi.In a given Resource Allocation Graph:
- If graph contains no cycles then there’s no deadlock
- If a graph contains a cycle then there are two possible situations:the first one,if there is only one instance per resource type, then deadlock can occur.But,if there are several instances per resource type, there’s a possibility of no deadlock.For example,
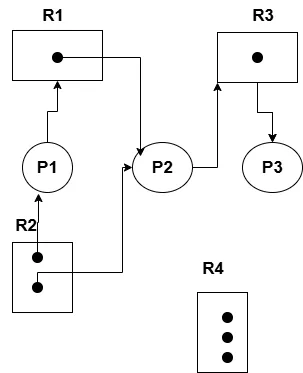
Resource Allocation Graph
In the above graph
- Processes are P1, P2, and P3
- Resources are R1,R2, R3,and R4
- Edges:{P1→R1,P2→R3, R1→P2, R2→P1,R3→P3}
- In case of process states,P1 is holding an instance of R2 and is waiting for an instance of R1
- P2 is holding an instance of R1 and instance of R2, and is waiting for an instance of R3
- P3 is holding an instance of R3
B) Wait for Graph
If there is a single instance of each resource in a system, the resource allocation graph can be simplified into a wait-for graph. The wait-for graph is obtained from the resource allocation graph by removing the resource nodes and collapsing the corresponding edges. If a process Pi points to Pj in a wait-for graph, it indicates that Pi is waiting for Pj to release a resource that Pi needs. To detect deadlocks, the system periodically invokes an algorithm that searches for a cycle in the graph. If there is a cycle, a deadlock exists. An algorithm to detect a cycle in a graph requires n² operations, where n is the number of vertices in the graph.
Note:If there is multiple instances of a resource type in a resource allocation system, the wait-for graph is not applicable. Hence,a deadlock detection algorithm will be used with the following data structures:
- Available:available[j] is number of instances of resource type Rj.
- Allocation:alocation[i][j] is the number of instances of resource type Rj currently allocated to process Pi.
- Request:request[i][j] is the number of instance of resource Rj required by process Pi.
Here is the deadlock detection algorithm for multiple instance of resoure type:
- First,intialize:
- Work = Available
- Finish[i] == false for all processes i such that Allocation ≠0 ,otherwise Finish[i] == true.
- Find a process i such that:
- Finish[i] == false
- Request [i] <=Work,If no such i exists, go to step 4.
- if there is:
- Work = Work + Allocation[i]
- Finish[i] == true ,then go to step 2
- If there is no process found and
- if Finish[i] == false, then this i process is deadlocked.
For example,assume,we have 2 processes P1 and P2, and 2 resources R1 and R2.Total resources are R1 = 4 and R2 = 5 and Available resourcess = Total resource - total allocated resource.So, R1 = 4-2 = 2 and R2 = 5-3 = 2.
Allocation Matrix
| Process | R1 | R2 |
|---|---|---|
| P1 | 1 | 2 |
| P2 | 1 | 1 |
Request Matrix
| Process | R1 | R2 |
|---|---|---|
| P1 | 1 | 0 |
| P2 | 0 | 2 |
Based on the above two matrix table,P1 used 1 instance of resource R1 and 2 instance of R2.But,P1 still needs 1 instances of resources from R1.Again,P2 used 1 instance from R1 and R2 and needs 2 instances of resource from R2. Next,Based on the Banker's Algorithm we will check on by one like:
-
For p1:is request less than or equal to available,that means,is(1,0) less than or equal to (2,2), which is true.Hence, p1 is completed and we will update the available resources as (available = available + allocated), available = (2,2) + (1,2) = (3,4) .
- For p2:is request less than or equal to available, that means,is (0,2) less than or equal to (3,4), which is true.Hence, p2 is completed and we will update the available resources as (available = available + allocated),available = (3,4) + (1,1) = (4,5).
Note: After completing P1 and P2, available resources become (4, 5), which matches the total resources.Because, after all processes have finished and released their resources back.
2) Deadlock Avoidance
The operating system makes decisions at runtime to ensure that the system never enters into unsafe state that could lead to deadlock.
That means, before granting a resource request, the operating system checks if allocating the resource will keep the system in a safe state or not.Safe state means there exists a sequence of process execution that can complete without deadlock.
The Banker's Algorithm is a deadlock avoidance algorithm designed by Edsger Dijkstra.The algorithm is used in operating systems to safely allocate resources for processes without a deadlock. The following data structure are available in Banker's algorithm:
- Available:Number of available instances of each resource type
- Max:the maximum demand of each process
- Allocation:The number of instances of each resource currently allocated for each process
- Need:Which is the remaining resource need for each process,that is
Max-Allocation - Request:Current resources request made by a process
Based on this algorithm,when a process makes a request:
- First,check if the request is less than or equal to Need and Available resources
- Allocate the resources and update Available, Allocation, and Need
- Finally,check the system and if it is safe,grant the request otherwise deny it
3) Deadlock Prevention
It is a mehod in operating systems designed to prevent the deadlocks by removing at least one conditions such as Mutual exclusion,Hold and Wait, No Preemption,or Circular Wait.Becasse,deadlock will occure if those four conditions are true at the same time.
4) Deadlock Igronance
If there is a deadlock in the system,then the operating System will just ignore the deadlock and reboot the system in order to function well.
The method is called an ostrich algorithm. Because the system simply ignores deadlocks, like a bird that supposedly hides its head in the sand to avoid danger.
Interrupt Handling in a Concurrent Environment
An interrupt is a signal generated by hardware or software that alerts the CPU to give immediate attention to a specific event. When an interrupt occurs, the CPU temporarily pauses its current execution to handle the higher-priority task, and once the interrupt is serviced, it resumes the previous process. Almost every operation in a computer system involves interrupts, such as pressing a key on the keyboard or clicking a mouse button.In general interrupt can be:
- External Interrupt:Generated from outside the CPU by hardware devices such as keyboard input, mouse events,or disk input/output completion.
- Internal Interrupt:Comes from inside the CPU due to program execution or exceptional conditions such as division by zero, memory access violations, or overflow.
Interrupt handling is the process by which the operating system responds to an interrupt. It ensures that the CPU saves its current state and executes the appropriate Interrupt Service Routine (ISR), and then resumes normal execution. During instruction execution, the CPU may receive an interrupt request through the interrupt controller, which is a hardware component.
After completing the current instruction, the CPU checks if there are pending interrupts.If so, the interrupt controller signals the CPU, and the interrupt handler takes control to manage the event. In this way,input/output devices trigger the interrupt request line and the interrupt controller forwards the request to the CPU.Finally,CPU executes the corresponding ISR before returning to normal operation.Here is the interrupt handling mechanism:
- When an interrupt occurs from hardware or software, it triggers a signal to the CPU.
- The CPU saves the current context, including the program counter, registers, and flags, so the interrupted process can resume later.
- The CPU identifies the type of interrupt by consulting the Interrupt Vector Table (IVT), which provides the address of the appropriate ISR.
- The CPU transfers control to the ISR, a small routine designed to handle that specific interrupt.
- Once the ISR completes, the saved context of the process is restored.
- Finally, the CPU continues executing the program from the point where it was interrupted.
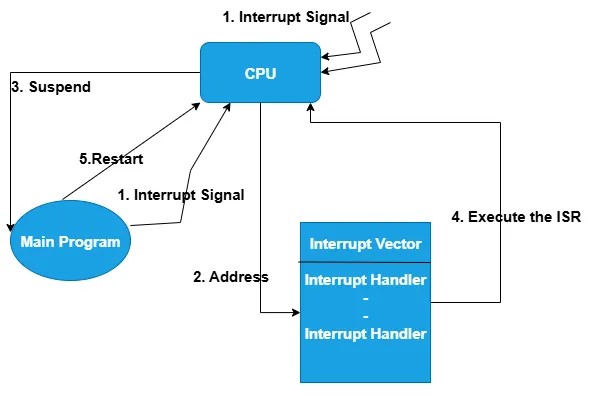
Interrupt Handling Mechanism
Producer-Consumer Problem
The Producer–Consumer Problem is a classic paradigm used to model cooperating processes. In this scenario, the producer process generates data that is later used by the consumer process, with both sharing a common buffer for storing the information.This buffer acts as a temporary storage, where the producer places items and the consumer retrieves them.In this case, the challenge is to ensure that the producer does not attempt to insert data into the buffer when it is already full, and the consumer does not attempt to retrieve data from the buffer when it is empty.The buffer can be of two types:
- Unbounded buffer: Has no practical limit on its size, allowing the producer to add items without restriction.
- Bounded buffer: Has a fixed size, meaning the producer must wait if the buffer is full.
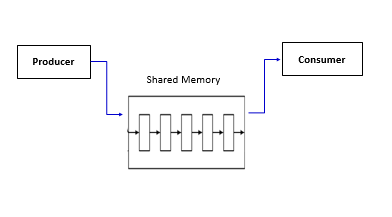
Producer Consumer Problem
To prevent conflicts and maintain accuracy,the producer and consumer need to coordinate their access to the shared buffer. That means,if the producer tries to add a new item but the buffer is already full, it should pause or go to sleep and wait until the consumer removes one or more items, at which point it will be awakened. Likewise, if the consumer tries to take an item but finds the buffer empty, it should pause until the producer adds an item and then wakes it up.For instance,
Producer
#define SIZE 100
int count = 0; //number of item inside the buffer
void producer(void)
{
int item;
while (TRUE)
{
item = produce_item();
if (count == SIZE)
sleep(); //means,producer should waits until the consumer removes an item.
insert_item(item);
count = count + 1;
if (count == 1)
wakeup(consumer); //means,notifies the consumer that an item is now available for consumption.
}
}
Consumer
void consumer(void)
{
int item;
while (TRUE)
{
if (count == 0)
sleep(); //means,waits until the producer adds an item.
item=remove_item(item);
count = count -1;
if (count == 0)
wakeup(producer);//means,notifies the producer that there is space available to produce more items.
consume_item(item); //process will use the item that was removed from buffer
}
}
Multiprocessor Issues
Challenges that arise when multiple CPUs share common resources in a multiprocessor system.These issues are mainly due to concurrent access to shared memory or I/O devices, which can lead to inconsistencies, conflicts, or performance bottlenecks.Some of them are the following.
- Race Conditions
- Deadlocks
- Processor Synchronization Challenges
- Interprocessor Communication Overhead
1) Race Conditions
Race conditions will occur when two or more processors access shared data simultaneously and the final outcome depends on the order of access.This condition finally leads to inconsistent or incorrect results.For instance,
public class AboutRaceconditions {
int counter = 0;
public void increment() { // Not synchronized and race condition can happen
counter = counter + 1;
}
public static void main(String[] args) throws InterruptedException {
AboutRaceconditions sharedCounter = new AboutRaceconditions();
Thread t1 = new Thread(new Runnable() { // Thread 1 is created but not running
@Override
public void run() {
sharedCounter.increment();
}
});
Thread t2 = new Thread(new Runnable() { // Thread 2 is created but not running
@Override
public void run() {
sharedCounter.increment();
}
});
t1.start(); //Thread1 begins execution concurrently
t2.start(); //Thread2 begins execution concurrently
t1.join(); //Main Thread pauses the execution of the current thread
t2.join();
System.out.println("Final counter value: " + sharedCounter.counter);
}
}
In the above example,Each thread tries to increment the counter twice.Since increment() is not synchronized, both threads can read and write the counter at the same time, causing a race condition.The final output may not always be 4; sometimes it could be 2, 3, or 4 depending on timing.
2) Deadlocks
A deadlock occurs when two or more processors or processes are waiting for resources that are held by the others, creating a circular waiting situation. As a result, none of the processors can proceed, leading to an indefinite halt in their execution.For example,
- Processor 1 holds Resource 1 and waits for Resource 2.
- Processor 2 holds Resource 2 and waits for Resource 1.
- Both processors are now stuck, unable to continue.
3) Processor Synchronization Challenges
Coordinating access to shared resources is complex and Requires mutexes, and semaphore, otherwise race conditions occur.
4) Interprocessor Communication Overhead
Processors need to exchange messages or coordinate via shared memory but,inefficient communication can slow down the system. Because,extra time and system resources required when multiple processors or cores exchange data or coordinate tasks.
Real-Time Issues
Real-time systems have strict timing constraints and managing these constraints introduces unique challenges to complete tasks within deadlines.The following are some challenges during real time operating system:
- Deadline Misses
- Priority Inversion
- Scheduling Overhead
- Resource Contention
1) Deadline Misses
In real time operating system,failing to complete tasks within their deadlines can lead to system failures.For example, Think about a car's anti-lock braking system, which tracks wheel speed sensors using a real-time operating system. In this case, the processing sensor data and responding within milliseconds is a tight deadline for the anti-lock braking system controller.
The brakes might not react fast enough if the real-time operating system overloads and misses the deadline to update brake pressure.Wheel lockup from this delay may result in a loss of vehicle control and possibly an accident.
2) Priority Inversion
It is a scheduling problem where a low-priority task holds a shared resource that a high-priority task needs and this forces the high-priority task to wait for the low one.Priority inversion can lead to significant delays and system inefficiencies.For instance,
Consider a low-priority task carrying out routine data logging and a high-priority task managing a spacecraft's vital sensor data.A common communication bus must be available to both. While writing logs, the low-priority task locks the bus.So,the high-priority task must wait for the low-priority task to release the bus before it can attempt to access it once it is ready.In systems where meeting deadlines is crucial,this can result in major timing problems.
3) Scheduling Overhead
It is all about the time spent in managing scheduling decisions and context switching.So,it
must be minimized to prevent impacting real-time task execution.For example,
The real time operating system must constantly switch between processing network packets, updating the display, and decoding video frames in a real-time video streaming application.Because,a large amount of CPU time is spent with simple switching tasks rather than processing the video if the scheduler is inefficient or runs too frequently.This overhead may result in delays, which would lower the quality of the video
4) Resource Contention
Multiple tasks may competing for limited resources and require careful management to avoid deadlocks and priority-related problems.For instance, If Task A and Task B try to use the port at the same time without proper coordination, they may block each other and finally, lead to deadlock.
Device Management
It is the process of implementation,operation and maintenance of a device by operating system.Here are the major tasks of device management:
- Device Driver
- Device Allocation and Sharing
- Input Output Management
- Interrupt Handling
1) Device driver
It is a software component that controls a particular type of device that is attached to a computer. For a computer to function correctly, device drivers are necessary.Furthermore, the corresponding hardware will not function as intended in the absence of a device driver. Device drivers give the attached hardware a software interface through which other applications and operating system can access its features.
For instance,printers, keyboards, and mice has device driver. Despite their small size, these programs allow a computer to communicate with hardware, networks, storage, and graphics. Device drivers are operating system specific and hardware-dependent. Through a computer bus or a communications subsystem that is attached to the hardware, they can interact with computer hardware.
Most of the time, drivers install themselves without any extra help.But,some drivers,need an update from time to time.For a computer to interface and communicate with particular devices, device drivers are required. They specify the protocols and messages that the computer,the operating system and applications can use to communicate with the device or send commands for it to perform. They also manage messages and device responses before sending them to the computer.The corresponding hardware device connected to a computer will not function if the device driver is not functioning properly.
Device Driver
From the above diagram,the application sends a system call to the operating system to request an operation such as read or write.Then,operating system forwards this request to the appropriate device driver, which translates it into hardware-specific instructions for the device. Once the device completes the operation, it returns a status message through the driver, which is passed back to the operating system and finally delivered to the application.
There are different types of devices that have their own respective drivers as well such as Bluetooth, Mouse, Keyboard, Motherboard,Network card,Printer drivers,and so on.We can view the device driver of different device from windows operating system using Device Manager like:
- Open the device manager by pressing ctrl+alt+delete or win + X keys from keyboard
- Expand each category such as Display adapters, Sound, video and game controllers to view the drivers installed.
- Right click on specific device and then click on property → click on driver tab
2) Device Allocation and Sharing
Device allocation is the process of allocating particular devices to users or processes and it guarantees that every user or process has sole access to the necessary devices.When a process requests a device,
- the OS checks if it is available and allocate device to the process.
- If the device is not available the process will be placed in a waiting queue until the device is free and OS updates its device status table
Depending on the device type, device sharing is permitting several processes to access a device simultaneously or alternately.To share a device,operating system used the following techniques:
- Simultaneous Peripheral Operation On-Line(SPOOL):is an operating system method for controlling data between a computer and slower peripheral devices such as printers and disk drives.The operating system processes each request individually after storing them in a queue/spool similar to a disk buffer.
- Buffering:A temporary storage to hold data while it is being transferred and helps several processes share a device without having to wait a long time.
- Caching:It is a small and fast memory,which is regularly accessed by numerous processes that speeds up overall access times overall.
- Scheduling:Is a method,which operating system decides which process runs on the CPU.FCFS, priority, and other may be factors to determine which process receives the device first.
- Protection and Synchronization:OS ensures one process’s I/O doesn’t interfere with another.
3) Input Output Management
One essential element of any operating system is input/output management. It includes the methods and procedures an operating system employs to control the computer system's input and output functions, guaranteeing effective and efficient communication between hardware and software elements.
It is a collection of methods and components that an operating system employs to manage input/output devices such as keyboards, printers, disks, and network cards. The OS makes sure that input/output devices are used effectively, fairly, and securely because devices operate far more slowly than CPUs and memory.Operating system component of input/output management ensures uninterrupted communication between the CPU, memory, and peripheral devices while hiding device-specific information from the user through techniques including interrupts, DMA, buffering, and scheduling..
4) Interrupt Handling
Interrupt handling is another important task of device management. An interrupt is a signal sent by hardware or software when a process or event requires immediate attention. The operating system responds to these signals through a procedure called interrupt handling, which manages the device and ensures that normal CPU operations resume smoothly afterward
Characteristics of Serial and Parallel Devices
- Serial Devices:are an input/output device that transmits data one bit at a time over a single communication line or channel. Serial devices are simple to use and relatively inexpensive, but their data transfer rate is slower compared to parallel devices. To connect a serial device to a computer, a serial port is used, which allows data to be sent bit by bit over the single communication line.For example,USB(universal serial bus) keyboard, mouse,and other
- Parallel Devices: parallel device are also an input/output device that transmits multiple bits simultaneously over several lines or channels. It provides faster data transfer than serial devices, but they are more expensive and complex due to the multiple wires required. To facilitate this, a parallel port is used, a physical interface that allows a parallel device to send and receive data concurrently across multiple communication lines.For instance,internal computer buses and older parallel port printers.
Abstracting Device Differences
Hardware abstraction is about providing a consistent interface for the operating system to interact with different types of hardware devices,regardless of their unique characteristics.The operating system uses an abstraction layer usually through device drivers or interfaces to hide device-specific details and offer a standard set of functions instead of dealing with the low-level operation of each device.
The Hardware Abstraction Layer,which serves as a link between the operating system and hardware,implements this abstraction.It controls interrupts,guarantees hardware independence,and converts operating system requests into commands tailored to a particular device.By doing this, the operating system can support numerous devices of the same type without requiring the kernel to be modified.For example,
Because hardware abstraction layer offers a consistent interface, a disk drive whether serial advanced technology attachment(SATA) or solid state drive(SSD) can be accessed using the same opearting system file system calls.Similarly,hardware Abstraction Layer provides a standard method of accessing network adapters,printers,and keyboards.
Buffering Strategies
Buffering is a technique,where data is placed in temporary storage,making it quicker to access than directly from the original source.This process improves the efficiency of input/output devices.The main types of buffering are:
- Single buffering
- Double Buffering
- Circular buffering
- Adaptive buffering
1) Single Buffering
This is the most basic kind of buffering,in which only one buffer is used to transfer the data between two devices.When a user process issues an input/output request,the operating system assigns a buffer in the system portion of main memory to the Operation.For instance, while data is being read into memory from a slow disk, the disk stores the data to a buffer, which the CPU later reads.The CPU will have to wait for the data to be written to the buffer before continuing if it is faster than the disk.
2) Double Buffering
Is a buffering technique that reduces waiting time by temporarily storing data in two buffers,enabling two devices to function simultaneously.A double buffer is commonly used in situations where computers prefer process data in chunks than the full program and this makes the program run faster.A device's overall throughput is increased and bottlenecks are avoided when multiple buffers are used. A bottleneck is a problem that arises when a computer slows down due to an excessive amount of data entering to a source.For example, Program B can be written while Program A is being read, and Program A can be written while Program B is being read. This makes it possible for both activities to take place simultaneously in separate places.
3) Circular Buffering
With circular buffering,data can be transferred continuously between input and output devices. This process continues through the buffers in the queue,and the consumer reads the data once it reaches the final buffer. In this type of buffering,the buffer is regarded as a circle and has a set size.data is retrived at the read pointer by the consumer and written at the write pointer by the producer.The pointers loop back to the beginning when the buffer's end is reached,makes it possible for data to be saved and used indefinitely.For example, In network communication,the incoming packets are stored in a ring buffer until the CPU processes them.
4) Adaptive Buffering
Is a technique in which the buffer size or strategy is adjusted dynamically based on the speeds of the producer and consumer.The operating system monitors the data transfer rates, and if the producer is sending data quickly,it increases the buffer size to prevent overflow.Accordingly, the operating system also adjust the buffer to avoid idle memory when the consumer processes data faster.For example,in systems designed for high-speed data acquisition,adaptive buffering adjusts memory usage dynamically to efficiently handle sudden bursts of data.
Recovery from Failures
It is method and procedure an operating system employs to return a system to its proper state following hardware,software,or system errors.This guarantees minimal downtime,data integrity,and business continuity.
The failure can be hardware malfunctions like power outages,memory problems, and disk crashes,software failures include operating system issues,bugs,and application crashes,or Human error such as Inadvertent deletion,incorrect setup.For such type of failure,we can use the following recovery techniques:
- Checkpointing:Is used in banking operations to periodically save the state of all activities,so that if a failure occurs,the system can restore to the last saved checkpoint.
- Write-Ahead Logging:In this case,modifications are first progressively written to a log file,which is write-ahead log before being made to the underlying database or file system.This technique is used to give gurantee even if the system crashes at midway,the database can recover using the log.
- Backups:Data copies are stored on separate media.Enables restoring lost or corrupted data after a major failure.For the case of operating systems failure,we can use system restore points or backup images to recover from failures
File Systems
A file is a named collection of related data stored on secondary storage devices such as magnetic disks, tapes,or optical media.Essentially,a file represents a sequence of bits,bytes,lines,or records,with its meaning defined by the creator and the user.In an operating system,a file serves as the fundamental unit of storage that contains data,information,or instructions.Files are managed by the file system and may take various forms,including text files,binary files,executable files,images,audio or video files, database files,and system files.
Note:For any type of file,there is a descriptor or attributes called Metadata.It is data about data and describes the properties and information of a file rather than the actual file content.
File System is the method and structure that an operating system uses to organize,store,manage,and retrieve data on storage devices such as hard drives,or USB drives.It provides a structured way to store,retrieve,and manipulate files efficiently.
File System Architecture
From the above diagram:
- User Application:Is simply a program that request read or write file operations.For example fopen("f.txt") system call
- Logical File System:Is part of the file system that both users and applications interact to it and manages metadata,file names,directories,and access permissions.For instance,"C:\Users\Documents\f.txt"
- Virtual File System:Is an abstraction layer in an operating system that acts as a bridge, allowing different file systems to work under a single interface.
- Physical File System:Handles the actual storage of data blocks on the disk.
- Storage Device:Is a place where files are stored physically.
Currently,the most popular file systems are:
- File Allocation Table(FAT):An older file system used by older versions of Windows and other operating systems.
- New Technology File System(NTFS):A modern file system used by Windows.It supports features such as file and folder permissions,compression and encryption.
- Extended File System(ext):A file system commonly used on Linux and Unix-based operating systems.
- Hierarchical File System(HFS):It is built on a hierarchical directory structure, where files are grouped in a tree-like structure with directories and subdirectories.For example,A file system used by macOS.
- Apple File System(APFS):A new file system introduced by Apple for their Macs and iOS devices.
File Operation
In Operating System,file operations are set of actions that the operating system allows users and programs to perform on files such as Create,Open,Read,Write,Delete,Close,Append,Rename,and Copy/Move.
File Organization
File can be organized inside storage in different fashion.The arrangment defines how records are placed,accessed,and managed to improve efficiency and performance.The following are some of them:
- Sequential File Organization:Documents are kept in a sequential order and access is easy,but searching takes a while.
- Direct File Organization:This method locates a record's storage location by using a hash function on a key field and enables incredibly quick access.For instance,database index files uses a hash function on a key field to determine where a record is stored.
- Indexed File Organization:To find records fast,an index is made,similar to a book index and permits access in both a sequential and random manner.For example,the catalog system at the library is one example.
- Clustered File Organization:In this technique,similar documents are kept in close to one another,that enhances relevant data access performance.For example,the customers and their order information is stored together.
Content and Structure of Directories
To arrange files and subfolders in a hierarchical structure,a directory is a unique container.In order to facilitate effective file retrieval,the directory structure of the operating system controls file names,locations,security settings,and other crucial information.It is a special kind of file that contains metadata about the files and subdirectories.The file name,file type,file size,location,access timestamps,and access permissions that specify users read and write operations are all common examples of metadata.
In a computer's file system,a directory is a unique file that maintains track of other files and subdirectories.It stores details about each file,including its name,type,size,location on disk,creation or modification dates,and access permissions,functioning similarly to an index or catalog. Directories used in the organized organization of files,which facilitates data management,access,and location for both users and the operating system. The operating system uses directories to track where files are stored,just like using folders to organise papers.There are different types of directory structures that help organise and manage files efficiently:
- Single-Level Directory
- Two-Level Directory
- Tree-Structured Directory
- Acyclic Graph Directory
- General Graph Directory
1) Single level Directory
Single-level directory is the simplest directory structure, all files are stored in the same directory, which makes it easy to understand and manage. However,a single-level directory has a major limitation when the number of files grows or when multiple users share the system.Since all files reside in the same directory,each file must have a unique name.For example,if two users try to name their dataset "test," the uniqueness rule will be violated.
Single Level Directory
2) Two level Directory
In a two-level directory structure,each user has a separate User File Directory (UFD) containing only their files.A Master File Directory stores entries for all users and points to their respective UFDs,preventing filename conflicts between users.But,in this directory structure a user is not allowed to share files with other users.
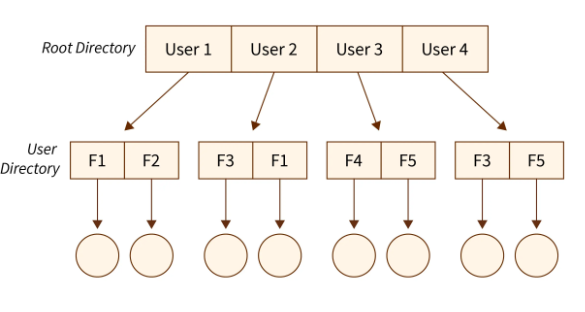
Two Level Directory
3) Tree Structured Directory
The tree directory structure is the most common in personal computers.It resembles an upside-down tree,with the root directory at the top containing all user directories.Each user can create files and subdirectories within their own directory but cannot access or modify the root or other users directories.
Tree Structure Directory
4) Acyclic Graph Structure
The Acyclic Graph directory structure in operating system is created to address the limitations of the tree-structured directory,including the inability to have many parent directories and users to exchange files. When a directory or file has multiple parent directories,it can be a shared file in a directory that is pointed by other user directories that have access to that shared file through the links provided to it.
Acyclic Graph Directory
5) General-Graph Directory Structure
The general-graph directory can have cycles,which means that a directory permits the construction of a directory within a directory,in contrast to the acyclic-graph directory,which avoids loops.File management and navigation may become more difficult as a result.
General Graph Directory
File System Techniques
The methods and techniques used by an operating system to organize,manage,and store data on hard drives and USB devices.It makes it possible to handle storage devices and their contents in a flexible and effective manner.The following are some of the techniques:
- Partitioning
- Mounting and Unmounting
- Virtual File Systems
1) Partitioning
It is logical division of a physical storage device.Each partition can host a different file system,enabling multiple operating system.
2) Mounting and Unmounting
Mounting is the process of connecting a file system to a mount point,which is a directory in the current file system hierarchy, so that the operating system can access the file system.Applications and users can access files on that file system as though they were a part of the main directory tree once they have been mounted.In Windows,mounting typically occurs automatically when a storage device such USB drive is connected.Because,windows mount it to an empty folder on NTFS partition or gives it a drive letter.Detaching a file system from the operating system and rendering it inaccessible until it is mounted again is known as unmounting.
3) Virtual File Systems
It is an abstraction layer that helps applications to use many file systems without worrying about the underlying details.Because,virtual file system offers a consistent interface to various file systems.
Memory-Mapped Files
In normal situation,we use standard system calls like read(),seek(),open(),and so on to perform a sequential read of a file present on the disk. Memory mapping is a technique that allows a part of the virtual address space to be associated with a file logically.It is a mechanism in which a file,is mapped directly into the virtual memory space of a process and enables the program to access the file’s contents as if it were part of the process’s memory,without explicitly calling the traditional read() or write() system calls.Such type of files are work based on the following techniques:
- Mapping the File:To represent the file,the operating system first allocates a range of virtual addresses in the process's memory using CreateFileMapping() in windows.Next,A piece of the file is represented by each virtual memory page, which is typically 4 KB in size.
- Access via Pointers:Once a file is mapped into memory,the program can read from or write to it using normal memory operations,such as pointers or array indexing.
- On-Demand Loading:Entire files are not instantly loaded into physical RAM.A page fault occurs because the operating system only loads pages into RAM when they are accessed.
- Automatic Synchronization:Depending on the flags specified during mapping,changes done in memory may be automatically copied back to the disk file.Multiple processes can view and share each other's changes when they map the same file as shared.
Special-Purpose File Systems
As the name implies,these file systems are designed to meet specific needs beyond general file storage.They optimize performance, reliability,or functionality tailored to particular applications or hardware.The most commons are:
- Network File Systems: Enable file sharing across networked computers.
- Distributed File Systems: Provide unified access to files stored across multiple servers.
- Real-Time File Systems: Guarantee timely access for real-time applications.
- Flash File Systems: Optimized for flash memory devices, handling wear leveling and error correction.
- Encrypted File Systems: Provide transparent data encryption for security.
Naming,Searching,and Accessing a File
Naming is the process of giving each file in a file system a distinct identity so that the operating system can identify and control it.To specify the type of file,file names may contain extensions like.txt,.jpg,or.exe.
Searching entails finding files inside the directory structure using information, attributes, or names. The file system's indexing algorithms and directory structure such as tree,graph,two-level,or single-level affect how efficiently searches can be conducted.
Accessing files involves reading or writing data.This can be done in several ways:directly by jumping to any part of the file,sequentially by reading records one after another,or by using memory-mapped methods,which map the file into memory so programs can interact with it using normal memory operations like array indexing or pointers.
Backup Strategies
It is a prearranged techniques for making copies of data that can be restored in the event of system failure,data loss,or corruption.Backup strategies play a crucial role in disaster recovery and data management for both individual and corporate systems.The following are common back up types:
- Full Backup
- Incremental Backup
- Differential Backup
- Mirror Backup
1) Full Backup
It is a type of backup in which all data from the selected files,folders,or system is copied to a backup storage location.It captures the entire dataset at a specific point in time.
2) Incremental Backup
Backs up only the data that has changed since the last backup of any type.It reduces the backup time and storage requirements.For instance,if we have a folder called AA containing files that you update daily.On the first day, a complete backup is done,and then on the following days,only the files that have changed,like file1.doc,are backed up using an incremental backup.
3) Differential Backup
It is a way of backing up all changes made since the last full backup.Differential backup comes from the concept that only specific data that is different is copied.It start its operation from an initial full backup,which is the process of making a copy of all objects in a file system used to store data.For example,if you made full backup on monday, tuesday's differential backup duplicates all the files changed since mondays's full backup.
4) Mirror Backup
A mirror backup is a type of backup,where an exact copy of the source data is maintained on the backup storage. Unlike incremental backups,the mirror always matches the current state of the source files added,modified,or deleted in the source are reflected exactly in the mirror backup.
System Security
Providing protection for computer system resources such as the CPU,memory,storage devices,software applications, and most importantly the data and information stored within the system is known as computer security.If unauthorized users are able to run programs,they can cause serious damage to both the system and its data.For this reason,a computer system must be safeguarded against viruses, worms,malicious access to memory,and other unauthorized activities.
System security focuses on preserving the integrity and confidentiality of the operating system.While it’s impossible to guarantee complete protection against all threats or unauthorized access,a system is deemed secure if its resources are reliably accessed and utilized solely for their intended purposes. A computer system may encounter the following violations:
- Threat:A program that has the potential to cause significant damage to the system.
- Attack:An attempt to break security and use resources without proper authorization.
Policy/Mechanism Separation
A key design principle in security is policy/mechanism separation,which separates what should be done as a policies from how things are done as a mechanisms.Because,policies are guidelines that determine security decisions that can be modified or altered without affecting the underlying security infrastructure.This separation encourages system modularity,flexibility,and maintainability.
For instance,the CPU scheduler in an operating system,where the policy is the scheduler,which determines which process runs next and the mechanism is the dispatcher, which handles the process context switch.
Security Methods and Devices
To prevent unwanted access,damage to computer systems,networks,and data,security techniques and tools are crucial.Security methods are strategies and procedures used to protect data and assets.It consists of firewalls,intrusion detection systems, antivirus software,encryption,authorization,authentication,and access control systems.
Security devices,on the other hand,are the hardware or physical instruments that are utilized to put these strategies into practice.For example,hardware firewalls,smart cards,security tokens,and biometric such fingerprint or iris recognition devices.We used security techniques and tools to guarantee the availability,confidentiality,and integrity of data,creating several lines of defense that lower the possibility of cyberattacks.
System Security Mechanisms
- Authentication:It is the process of confirming a user's or system's identity before allowing access and it usually involves the use of cryptographic keys,biometrics,or passwords.
- Access control:Refers to the privileges or authorizations that are provided to users or processes.It is defining the actions such as read,write,execute,and delete that can be permitted to take on resources.
- Protection:The collection of controls that limit users and programs access to the resources that a computer system has designated,including memory,files,and devices.
Models of Protection
It is a formal methods for establishing and implementing security needs or access control.The following are common protection models:
- Access Matrix Model:The access rights of each subject to an object are indicated by each cell in the access matrix model, which displays subjects (users or processes) and objects (resources) as a matrix.
- Capability List model: outlines the objects and rights that each subject can exercise.In this case,each subject like a user has a capability list, which contains capability entries.
- Access Control List model :Is a security mechanism that defines which users or system processes are allowed to access specific resources and what operations they can perform.Basically each resource like a file has a list that enumerates permissions linked to different users.
- Bell-LaPadula and Biba:Serve as a framework for designing systems that ensure secure,regulated,and consistent access control.While the Biba model focuses on maintaining data integrity,based on simple integrity property,
NO READ DOWNand star integrity property,NO WRITE UP,the Bell-LaPadula model is concerned with safeguarding confidentiality based on simple security property,NO READ UPand star security property,NO WRITE DOWN.
Memory Protection
An essential feature of operating systems is memory protection,which enables them to prevent the use of one storage type by another.In modern operating systems,memory protection is essential.Because,it allows multiple programs to operate simultaneously without affecting their own storage space. Preventing an application from accessing RAM without authorization is the main objective of memory protection.The operating system of the computer will halt and terminate the process whenever an approach tries to use memory that is not authorized to access.Memory management units are typically employed for memory backup and are part of an instruction set that maps the digital addresses used by a program.As a memory protection,we can use the following ways:
- Segmentation
- Paged Virtual Memory
- Protection keys
1) Segmentation
Memory is divided into sections,each of which may have a unique set of access privileges.For example,a user data segment may have been marked as read-write,but an operating system kernel segment may have been read-only.
2) Paged Virtual Memory
In paged virtual memory,memory is separated into pages,and each page can be stored in a separate location within physical memory.The operating system makes use of a page table to keep track of where pages are stored.This allows the operating system to relocate pages to different locations within physical memory,where they can be protected from unwanted access.
3) Protection keys
A collection of bits known as encryption key is present on every RAM page.These components can be used to control page accessibility.For example,a protection key could be used to indicate whether a document is to be read or written to.
Encryption
Is the process of transforming human-readable plaintext into unintelligible text or ciphertext.Encryption modifies readable data to make it random.A cryptographic key,which is a set of mathematical values that the sender and the recipient of an encrypted message agree upon,is necessary for encryption.
The mathematical process of encryption uses a key and an encryption algorithm to change data.A party with the correct key can decrypt the encrypted data and convert it back to plaintext, even though encrypted data seems random. This is because encryption works in a logical and predictable manner.

Encryption Process.
A string of characters called a cryptographic key is used in encryption algorithms to change data so that it appears random.It encrypts data,just like a physical key,and only the appropriate key can decrypt it.The following are the two types of encriprion:
- Asymmetric encryption:Also known as public key encryption,which uses two keys:one for encryption and another for decryption.Whereas the encryption key is made publicly available for anyone to use and the decryption key is kept confidential.
For example,if Yilma wants to send a confidential message to Abebe using the RSA algorithm,Abebe first shares his public key with Yilma.Yilma then uses Abebe's public key to encrypt the message and sends the encrypted message to Abebe.Abebe decrypts the message with his private key,which only he possesses.Only Abebe can read the message even Yilma cannot decrypt it since he doesn’t have Abebe’s private key. - Symmetric encryption:All communicating parties utilize the same secret key for both encryption and decryption,which uses a single key.For instance,if Yilma wishes to communicate with Abebe,they already have a secret key in common.Using that key,Yilma encrypts the message and Abebe receives the encrypted message from him.Abebe reads the original message after decrypting it with the same key.The message cannot be read if it is intercepted by someone without the key.
Recovery Management
It is the procedures and systems intended to return a system to a consistent and operational state following a malfunction or interruption.It involves detecting problems,implementing corrective actions,and ensuring data integrity through techniques such as system restoration and backups.The recovery manager plays a crucial role by helping the system to return to a stable and reliable state
Linux Operating System
It is a Unix-like, open-source operating system and contains the following common components
- The kernel:is the central component that controls memory, CPU, hardware resources, and processes. It typically serves as a link between software and hardware. System calls, device drivers, and process scheduling are a few examples.
- File systems:part of the operating system which is used to arrange and store data on storage devices.For example, XFS, Btrfs, and Ext4.
- Shell:It is the command-line tool that links the user to the kernel. It reads the commands you type, interprets them, and passes them to the kernel to execute.For example, Bash, Zsh, and Sh.
Linux can be installed using a virtual machine like VirtualBox, which allows Linux to operate as a guest operating system within another host operating system for testing and experimentation, or by utilizing a Live CD/USB, which enables running the OS directly from the media without installing it on the hard drive.
The Command-Line Interface (CLI), which employs text-based commands via a shell like Bash or Zsh, or the Graphical User Interface (GUI), which offers visual components like windows, icons, and menus for simpler navigation and operation, are the two ways we can interact with Linux.
Linux distributions include Kali Linux for security testing, Ubuntu and Fedora for general usage, and Debian for stability. Although each distribution may employ distinct desktop interfaces such as GNOME or KDE and package formats such as.deb or.rpm, they all fundamentally use the same Linux kernel.The general syntax for launching an action on Linux with a command with arguments is command argument1, argument2...
Note:Linux commands are case-sensitive, so ls and LS are regarded as distinct commands, and always insert a space between the command and its arguments in the shell.
When the shell is prepared to receive commands from the user, it displays the initial shell prompt in Linux, which is either $ or #. It shows that the shell is waiting input.In this case,the typical user prompt is $, and the root prompt is #. For instance, yilm is the username, ubuntu is the hostname of the computer, ~ denotes the current directory , and $ is the typical user prompt in yilm@ubuntu:~$.The # sign denotes root or superuser access if the user is root, such as root@ubuntu:~#.Here are commonly used Linux commands:
- date:used to show the current date and time.
- pwd:to display the present working directory.
- ls:to list files and directories in the current location.
- cd:to change the current directory.
- mkdir:to create a new directory.
- rmdir:to removes an empty directory.
- touch:creates a new empty file.
- cp:copies files or directories.
- mv:moves or renames files/directories.
- rm:to delete files or directories.
- echo:displays text or variables on the screen.
The Ubuntu desktop includes several key components that make it user-friendly and easy to navigate:
- Menu Bar: Shows notifications, network, date/time, application indications, and system menus.
- Launcher:A side-mounted vertical bar with shortcuts to frequently used apps and active processes.
- Desktop: The primary location of files, directories, and program windows.
- System Tray: Displays icons for system status, such as network, volume, and battery.
- Application Windows: Programs run in these windows, which have minimize, maximize, and close buttons along with title bars.
- Workspaces: Enables the organization of open programs across several desktops.
In Linux, we can use the following to change from regular user to root user and vice versa:
- To become a root instead of a regular user,type su command and enter the root password.
- To return to an ordinary user from root,simply type exit and press enter.
Here is a simple step to create user and group name in linux:
- sudo groupadd groupname is used to create a group.
- Use sudo useradd -m -G groupname username to create a new user and add it to the group.In this case,-m establishes the user's home directory. Additionally, -G places the user in the designated group.
- sudo passwd username to create a password for the user.
- Make a folder in the user's home directory like mkdir /home/username/foldername
- Make a file in that folder like touch /home/username/foldername/filename.txt
- Grant the user ownership of the file and folder as sudo chown -R username:groupname /home/username/foldername.For instance,to give read-only permission to the folder, use chmod 544 myfolder.This 544 indicates read permission for owner, group, and others, no write or execute.
After we create user and group,we can use ls -l command to list files and directories in detailed format. like:
- Permissions and file type such as -rw-r--r--
- File size in bytes;
- Owner name and Group name;
- Number of links to the file;
- Date and time of last modification;
- File or directory name
For instance,in -rw-r--r-- 1 yilm yilm 1024 Nov 28 10:00 example.txt, example.txt is a normal file with read/write permissions for the owner, is 1024 bytes in size, belongs to the user and group yilm, and was last edited on November 28 at 10:00.
Common commands for displaying user and group are
- cat /etc/passwd: Displays a list of all user accounts on the system.it Shows username, user ID, group ID, home directory, and default shell.
- cat /etc/group:Displays a list of all groups on the system and Each line contains group information in the format:
The chmod tool in Linux allows you to modify file permissions that regulate owner, group, and other users' read, write, and execute access.The numeric mode, such as chmod 754 file.txt, is the most popular method.For the owner, group, and others,permissions are represented by each digit.
Note: In every operation, we have to check the present working directory using pwd command
